
In 2010 I started API Evangelist, as part of my effort to better understand the world of APIs. I was looking to not just the technology of how it was done, I saw there were plenty of people doing this. I wanted to better understand the business of APIs, and how popular APIs were finding success with their business models, developer outreach, and other aspects of API operations–going well beyond just the technology.
API Evangelist started simply as a blog. I was not a big fan of WordPress, as I knew it can be quite a security target, and as a platform, for a programmer like me, can be more difficult to get even the simple things done. With this in mind I started the first API Evangelist API, by following the same advice that I would be giving to my potential audience.
api.apievangelist.com/blog/
Quickly I needed some additional APIs, to keep track of some of the players I saw emerging across the landscape. In 2010, the most important piece of the puzzle, when it came to the business of APIs (after the APIs themselves) was the growing number of API service providers, who were popping up to deliver much needed services to API providers. To support my work I added a couple more API endpoints.
api.apievangelist.com/serviceproviders/
api.apievangelist.com/apis/
Tracking on APIs wasn’t that critical, as it was something ProgrammableWeb already did, but I still preferred to track on some addition details for my own needs. When it came to deploying my own APIs, I kept the as simple as possible, using the backend that I knew best – the LAMP stack. I was already running several websites on Amazon Web Services, so I chose to deploy my servers and database using Amazon, using a pretty proven formula for delivering a backend stack.
LAMP Stack - MySQL (RDS) + PHP / Linux (EC2)
PHP may not be the choice of API champions, but I was fluent in it, and I new that when the time came, and I open sourced the back-end for API Evangelist, that if everything was straight up LAMP stack, I would reach the widest possible audience. Now, with my base API infrastructure in place, I began designing, and deploying other APIs I needed to track on the world of APIs. I needed to track on some of the open source tools I was finding so I added a new endpoint.
api.apievangelist.com/tools/
After tooling, links were quickly becoming a big challenge for me. I needed a way to track on links to not just stories, but also events, white papers, presentations, and other resources that I was referencing in my research. I needed another API that I could use to store links from across the space.
api.apievangelist.com/links/
Once my links API was in place, I also began using it for a number of other functions, showing me that I quickly needed more functionality beyond simply storing a title, description, and URL. As I was monitoring the space, I saw that I would needed a way to curate links to important stories across the fast growing space each week–resulting in me adding a new layer to my links API.
api.apievangelist.com/links/curation/
Beyond tracking on important links, and curating the news each week, I started to see that many of the links I placed in my blog posts were disappearing. The API space moves really fast, and many of the API companies that were being acquired or shutting down, were simply disappearing. I didn’t like my readers stumbling across dead links, so I added another layer to my links APIs to help, which I called.
api.apievangelist.com/links/linkrot/
Part of the linkrot API operations, was taking a screenshot of each website referenced, so when it disappeared, I could easily replace it with a popup screenshot of what used to be there. To support this I was using a number of 3rd party screenshot APIs, which after using three separate ones, each shutting down, I eventually created my own screen capture API.
api.apievangelist.com/links/screenshots/
Beyond links, I was hitting on similar problems with my service provider API. Some of the companies I tracked on were not APIs or API service providers, I needed a way to track on other types of companies. At the same moment I realized I also needed a way to track the individuals who were also doing interesting things in the space, as well as the companies they worked at, resulting in the creation of two new APIs:
api.apievangelist.com/people/
api.apievangelist.com/companies/
Similar to links, I created a new API that allowed me to centrally manage all the images I used. I store all my images on Amazon S3, but I needed a way to track not the URL, but also a plain english title, description, tags, and other metadata about images. I added another new API.
api.apievangelist.com/images/
Then, similar to my link system, I began having more advanced needs for images, which required numerous endpoints to be added, allowing me to better manage the visual side of operations for API Evangelist. Images are critical to my storytelling, so I hand crafted exactly the APIs resources I needed to get the job done.
api.apievangelist.com/images/resize/
api.apievangelist.com/images/crop/
api.apievangelist.com/images/compress/
There are too many APIs to list as part of this story. Ultimately over the last five years, I’ve added an ever increasing number of utility APIs that help me manage data and content across the API Evangelist network. Most of these APIs were custom developed, but some simply provided a facade for other public APIs, or open source software I had installed on the server.
api.apievangelist.com/images/conversion/
api.apievangelist.com/file/conversion/
api.apievangelist.com/url/parse/
api.apievangelist.com/database/backups/
api.apievangelist.com/log/sync/
api.apievangelist.com/dns/backup/
I was accumulating a pretty interesting stack of information, which I was using to power my own network, but I was the API Evangelist, without any public APIs. I wanted to open up my APIs to the public, and what better way to do it than to evaluating the API management providers I had been writing about, a process which resulted with me choosing 3Scale API Infrastructure. 3Scale had the features I needed like user management, analytics, and valuable service composition tooling, allowing me to craft different levels of access to my APIs for public usage, access by my partners, and of course for my own internal usage.

Using 3Scale I dropped an include file into my existing API stack, and with just a few lines of code I secured my APIs, and metered who had access, requiring registration for public or partner levels of access. To support this I launched a simple portal for the APIs I was making public. I didn’t release all of my APIs, only the ones I felt the public would be interested in.

I kept on working on my infrastructure, adding an increasing number of endpoints, building on existing APIs, evolving my APIs to help me better monitor the API space, organize information, and craft the stories that I publish each week to the API evangelist network. Eventually I had hundreds of endpoints, some of them well planned, but many of them just thrown up to support some need I had at the moment.
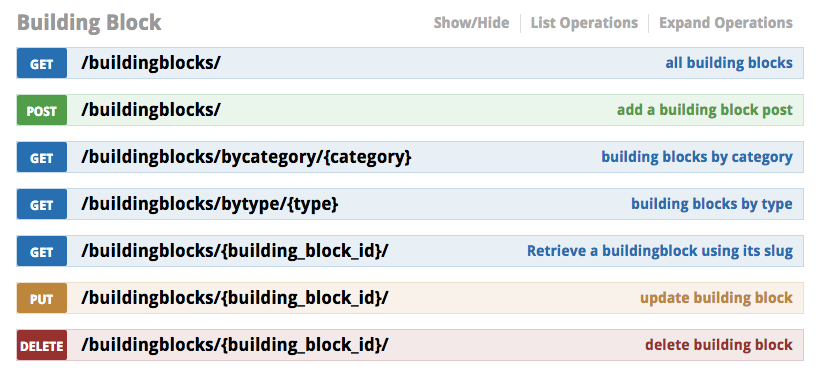
The API Evangelist API stack was growing more unwieldy by the day, and even though I am the sole developer, sometimes I’d lose track of what I had. I also struggled with consistency, I am not always the most regular guy when it comes to naming conventions, use of query parameters, headers, and other common illnesses you see in API design across the space. Another thing that was getting out of control, was my backend database.
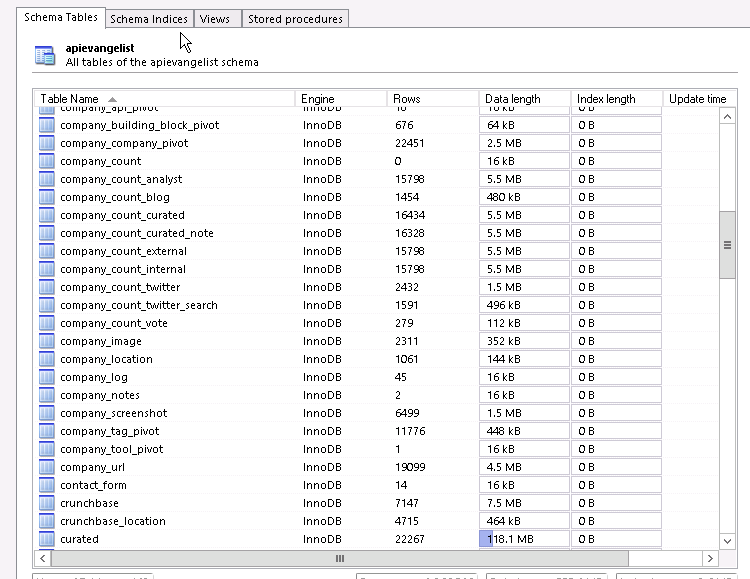
It was my database. I could do whatever I wanted. I just added tables, columns, and new databases as I saw fit–again, all without much consistency. I was growing a pretty large legacy code base, which was API driven, but API does not always equal better. You can just as easily build a monster with APIs, as you can with historical approaches to API design. Additionally, my architecture ran on a single Amazon RDS database instance, with a single Amazon EC2 Linux instance, serving up all the APIs.
![]()
If one API failed, all APIs failed. If I was running a large job against a single API, say creating screenshots, compressing images, or other CPU intensive processes, my other APIs suffered. Also if I rebooted the server, everything went dark. Which as a independent operator, is always very tempting.
![]()
I loved my evolving API stack, it did what I needed, but was increasingly looking like many of the legacy systems I had managed in the past, only this time it was all accessible through a single API stack. If my APIs did what I needed, this wasn’t a problem, but in my back of my head I knew eventually it would catch up with me. For now I ignored it, and moved forward comfortably numb (Pink Floyd).
Along the way I also discovered new tools for helping me manage my APIs, specifically my API documentation, by using Swagger. If I crafted a machine readable JSON definition for my APIs using Swagger, I could automatically generate interactive documentation for my APIs, that was always up to date.

Quickly I found Swagger to be much more than just a machine readable API definition format, that just can be used to generate interactive documentation, or the generation of client side code libraries. While it still fully isn’t realized, I saw that if I took an API design first approach, using Swagger, that it slowly was becoming a central truth throughout my API life cycle. This was just the beginning of a new world of API design, deployment, and management for me.
Along the way in 2014, Steve Willmott, the CEO of 3Scale and I developed a machine readable API discover format, which we called APIs.json. This new JSON format, was intended to provide a machine readable index of all APIs that exist within a single website domain.
Using APIs.json I could provide essential meta data about the domain an API operates in, as well as for each API endpoint available, like name, description, tags, and critical links to aspects of operations like the portal landing page, API documentation, code libraries, pricing, or terms of service. For each API I hand crafted an APIs.json, allowing me to publish a machine readable index of APIs that exist within my domain.

APIs.json immediately provided me with a very valuable index of my own APIs. Then I got thinking, what if I also indexed the public APIs that I depended on as well? So, I put around 50 public APIs to use, and nowhere did I have a comprehensive list of these APIs, especially not all the meta data for API operations including documentation, code libraries, pricing and terms of service, let alone a machine readable definition of the surface area using Swagger.
![]()
I now had three separate APIs.json files, one for my own internal APIs, one for my own APIs I offer up publicly, and a third for the distributed public APIs that I depend on for my operations. I didn’t just have a single index of my APIs, I had essentially mapped out all of my stack, providing me with a single location I could go to find all my APIs.
![]()
This isn’t just about providing the public with a discovery solution for my APIs, it is also about me understanding my entire surface area. Something that honestly, showed me what a mess much of my infrastructure was, but regardless, at least now it was mapped out and known, for good or bad. For the first time, I felt like there was potential for getting my house in order–then Docker happened.
![]()
The new containerization solution provided me a new way to look at my architecture. Rather than one big MySQL instance, and a support Linux / PHP / Apache server instance, I could deploy a single Docker instance, with many little LAMP nodes, each with the basic configuration I needed to run my APIs. Rather than having all my APIs served up via one server, I was able to essentially break up each API, and put into its own, independent container.
![]()
Sure, my APIs still ran on a single AWS EC2 instance, but now they each ran in individual Docker containers which could be easily fired up in separate instances, running in any infrastructure, something I would test out later. For now, I was happy knowing that I could slowly separate out each of my APIs, allowing them to act independently of each other, with hopes that a single API could fail, without bringing the entire stack to its needs. Conversely, each API could be independently scaled to meet my specific needs of just that API, without be forced to scale all my APIs.
At the same moment, another thought process was evolving, something that really wasn’t much different than what I could already do, but provided me a strong incentive for rethinking how I approached my architecture, something that was not just complemented by, but also facilitated by Docker containerization–Microservices.
![]()
Microservices is more philosophy, than a concrete technology like Docker, but it provides a healthy basis for thinking about how you design, deploy, and manage your APIs. With this in mind I set forth crafting my own definition, of just exactly what micro meant to me, something that is proving to be a very personal thing, evolving from individual to individual, and company to company.
minimal surface
minimal on disk
minimal compute
minimal message
minimal network
minimal time to rebuild
minimal time to throw away
minimal ownership
minimal dependencies
A microservice way of thinking, coupled with Docker enabled containerization, has allowed me to rethink how I design, and deploy my APIs. While I’m not fully subscribing to popular opinions around what is a microservice, it is allowing me to rethink many of my own architectural patterns. However this new way of thinking, came with some shortcomings, around how I uniquely identify API resources, as well as discover resources, but luckily I already had been working on solutions in these areas.
All of my APIs were already defined using Swagger, which essentially provided me with a fingerprint of each API, that I can use to uniquely identify each API, as well as quantify the entire surface area, such as how many endpoints, parameters, and details about underlying data model, and message formats. I now had, my solution for API identification, but what about API discovery?
As I contemplated untangling the legacy API mess I had created for myself, I was concerned that if I reduced the size of each API, spawning new APIs, I would eventually have over 500 individual APIs, potentially creating even more of a nightmare for myself. Luckily I had already started hanging these APIs onto an APIs.json file, something I can continue to replicate into smaller, more isolated groups, while also linking up using the APIs.json include collection. I would no longer have just three APIs.json files, I would have many nodes of APIs, indexed using APIs.json, with a master APIs.json as the doorway to my increasingly decoupled world.

As I got to work redefining my API stack, I couldn’t disrupt my current set of APIs I have deployed to API Evangelist, so I decided to publish this core set of tools under the KinLane.com domain. It actually makes sense, because many of the APIs are not directly related to API Evangelist, spanning larger work that I do. My brand is bigger than just API Evangelist, it is just one node underneath the Kin Lane brand.
![]()
After completing the first wave of converting my legacy API stack, using my new containerized, micro design approach, each complete with its own Swagger, and APIs.json, I end up with 25 separate APIs, with over 250 endpoints. This provided me with a next generation blueprint of my API stack, that I could easy follow, add to, and evolve over time.

As I carved off each API, defining the next generation I worked to keep as small, and self-contained as possible. My link API, became link, curation, and linkrot APIs, with additional supporting services for screen capture, pulling content, and other utilities as their own, individual endpoints.
/links/
/curated/
/linkrot/
/screencapture/
My images API is getting similar treatment and carving off many of the support utilities as stand alone features so that I can use them separately. While I may use resize, compress, and other utilities in conjunction with my core images API, many times this won’t be the case, especially if I open up to the outside world.
/images/
/resize/
/compression/
/filter/
This process of reducing the scope of my APIs isn’t just about size, it is also about isolation of services, keeping my APIs doing one thing, and doing it well. Allowing me to deploy, scale, and migrate my services exactly as I see fit. While my definition of a microservice may not be everyone else, it helps provide a guide for me as I’m evolving legacy APIs, as well as defining and evolving new ones. With my new stack, I can now begin to think about how I deploy my cloud infrastructure a little differently.
AWS = Containers
Google = Containers
Microsoft = Containers
I can easily fire up a Docker stack in both AWS and Google, both using the exact same LAMP stack configuration, and pull in each of my API definitions, allowing me to easily deploy, and migrate between cloud providers. To accomplish this, it isn’t as if I can drag one container from AWS to Google, I rely on Git, or more specifically Github to help me achieve this.
Each API lives as its own Github repository, with every aspect of its existence present either within the private master branch of the repository, and some of it available in a public gh-pages branch. Using Github I store the server side PHP code I will use when deploying each Docker container, but I also story the data model, data backups in the private, secure master branch of the repository.
![]()
At the center of reach Github repository is the APIs.json for the API, providing of index of not just meta data about the API, but its Swagger fingerprint, server code, client code, and other essential elements of operations. When I fire up a new Docker container, I reference where to find its server side API code, which also simultaneously provides it with the Github organization and repo where it can find its APIs.json index.
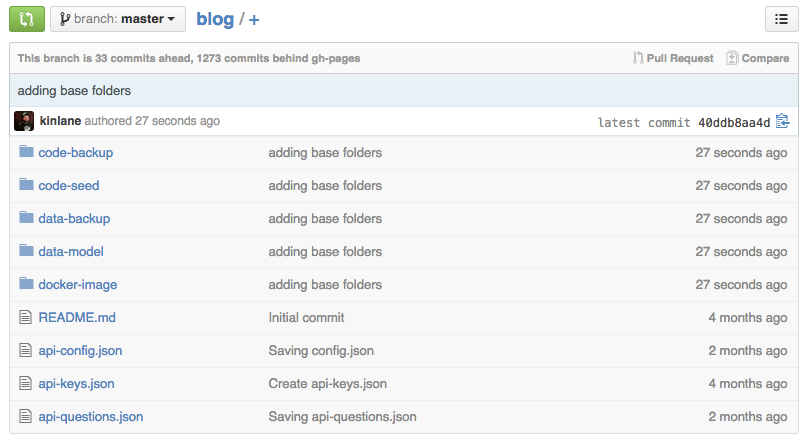
This approach allows me to easily fire up containers in any cloud provider that supports Docker, which is pretty much all of them in 2015. The best part of this, is I can also deploy locally in my own home or office, using a local server, or even via Raspberry Pi (work in progress).

Another important aspect of this evolution of my API stack, is that as I’ve decoupled my APIs, allowing them to reborn as a decoupled set of independent portable APIs, forever changing how I design and deploy my APIs, my API management is also undergoing the same treatment. You see, if my APIs can migrate and move, so does the API management layer that I use to orchestrate them.

To begin with, I need the basic ability to mange my API consumers. I need the basic controls for managing access to all the APIs contained within a stack, alongside all my APIs, as an equal resource.
**api.apievangelist.com/users/**
User Create
User Read
User Update
User Delete
With the ability to add, read, update, and delete users on my platform, I also need to the ability to manage each of the accounts. This way I can directly access each account within my API stack, but more importantly my API consumers can also manage their own accounts using the same APIs.
api.apievangelist.com/account/
Account Set Credit Card
Account Delete Credit Card
Invoice By Account
Invoice Line Item List
Invoice Payment Transaction List
A key part of my API management infrastructure is the concept of service composition. Using 3Scale I have created multiple tiers of access to APIs, allowing for a public free, entry level layer, as well as higher levels of paid, partner, and internal access. I need the details of these service plans I’ve created, including their features to move with my API infrastructure.
**api.apievangelist.com/services/**
Service Plan List
Service Plan Feature List
Service Plan Set To Default
As each of my API consumers register, and manage their API access, the next level of API access is handled through the application level management layer. 3Scale gives me the tools to do this, which I’ve extended as individual API endpoints.
**api.apievangelist.com/applications/**
Application Plan List (per isolated service)
Application List
Application Create
Application Read
Application Update
Application Change Plan
Application Key List
Application Key Create
Application Key Delete
Application Usage by Metric
There are plenty of other services that 3Scale API infrastructure gives me, but this represent the v1 API stack I need to help orchestrate this new, containerized, potentially distributed API stack I’ve setup for myself.

Eventually I’d like to see entire 3SCale infrastructure decoupled, similar to my stack, giving me, and my consumers to access all API management features, right alongside the other API resources I am providing–giving me a pretty complete stack. Now I’m ready for the higher level evolution of my APIs, between my two organizations.
![]()

With my new approach I can easily establish a new Github organization for API Evangelist, pick exactly the APIs I want, fork them to my new organization, deploy a new container server on AWS, Google, or wherever I need it, and have a brand new stack. I will use the same 3Scale API infrastructure account to manage both my Kin Lane and API Evangelist API stack, so other than deploying the individual APIs, there is no configuration needed, my API management follows my APIs.

All along the way, I’ve been on-boarding new API consumers, as well as migrated the users who have historically used my API Evangelist stack of APIs. Some of these users have shown interest in being able to scale their usage of some of my APIs. These tend to not be the core blog, or company APIs I’ve developed as part of my monitoring of the API space, they are other more utility APIs.
/screencapture/
/image/resize/
/api/swagger/
While many of my users are perfectly happy using these utility APIs via my API stack, some of them have expressed interest in being able to scale the API to meet the demands of their operations. Just as I will scale up Docker containers for my own needs, my customers are hoping to do this same, or possibly even deploy my API designs, in their own infrastructure – opening up a whole new level of API monetization for me.
![]()
I can even take this to the next level, and deploy entire API stacks for customers, their infrastructure or mine. Providing all APIs, via an a la carte menu, giving an entire new dimension to my API deployment strategy. I can deploy API stacks, exactly as I need them, for my own needs, or for my customers–using the same API infrastructure. The best part of this, is it isn’t just about deploying API infrastructure of my needs, my customers can get in on the API provider game.
![]()
My customers can start by consuming APIs, then evolve to deploying them within their own infrastructure, and when ready, they can open up these APIs to their own customers, and the way my 3Scale infrastructure works, I can switch them over to their own API management account at any time, with no changes needed. I just create a new top level account, change the master API management key from mine to theirs, replicate service levels, and their customers can start signing up, and consuming their APIs.
![]()
This approach to API deployment and management opens up not just a new way of monetizing APIs at a wholesale level, it opens up the power of being an API provider to my API community. Another interesting aspect of this approach is because each API comes complete with a machine readable Swagger API definition, and APIs.json file index, each API, and each API stack is easily discoverable, and open to the delivery of API focused services, from 3rd party providers.
![]()
In 2015, more API service providers are supporting Swagger, and other common API definition formats like API Blueprint, as a way to on board, configure, automate, and access valuable API services in the cloud, or even on-premise. While to many Swagger is a way to generate interactive documentation or client code libraries, it is being used by a growing number of companies for much, much more.
![]()
Using API Science I can import the Swagger files for my APIs, and generate the monitors I need to keep an eye on API operations. Once API monitors are setup, I receive regular emails per my account, and can embed dashboard tools for helping me visualize my platform availability.
![]()
Similar to API Science, using Runscope, I can import Swagger definitions into my account, and automate the setup of tests, which I can run as part of my regular platform monitoring and testing–saving serious time in how I monitor my APIs.
![]()
Postman allows me to import my Swagger definitions, and create ready to go API calls, where I can see easily understand the request and responses of all my API calls, collaborate with other API consumers on my team. Postman allows me to easily work with my APIs, without a UI, and with some of my APis, is how I engage – never quite needing a full UI.
![]()
SmartBear also allows you to import Swagger, and allow you to generate mock and virtualized APis, run testing, monitoring, performance, and security tests against your APIs. Using Swagger I can quickly configure a number of vital services I need to operate a healthy platform.

This is something that isn’t just machine readable, and can be translated into UI, browser, IDE, and other more human aspects of API integration and engagement.

While none of these service providers listed, currently support the importing of APIs.json, only Swagger – eventually they will. APIs.json will provide a single entry point that these API service providers can import not just one, but many APIs, and configure valuable services throughout an APIs life cycle. An example of this in action can be found using the APIs.io API search engine.

APIs.io provides an APIs.json import, allowing you to index all of your APis, and the supporting elements of API operations. Once indexed, APIs will be available to the public, via the open source API search engine. This is just the beginning of APIs.json enabled search, other providers are getting in the game as well.
![]()
With the next release of the WSO2 API management platform, API providers will be able to organize APIs, and export them as APIs.json collections, opening up for either listing in the public APis.io search engine, but also opening up for the deployment of private, internal API search engines using either APIs.io, which is open source, or the deployment of a custom solution. I have also begun delivering tooling that employs APIs.json, for delivering vital services along the API life cycle.

Using the Swagger Codegen project, which is an open source solution for generating client side libraries, I deployed an API that accepts any valid APIs.json file, and return seven separate client side libraries, from the Swagger definition. While these are by no means a perfect client solution, it provides a nice start for some developers to get going, eliminating some of the more redundant aspects of API integration.
An advantage of using APIs.json to index API operations, and on board API service providers, is that it can provide access to one, or many API definitions, as well as other aspects of API operations, like documentation, code, pricing. While many of these aspects are not machine readable, once an API has been imported into a service providers platform, these other elements can provide important references that service providers can use to determine next steps. I’d call this level of API service delivery a more inbound approach, but APIs.json also brings outbound effects to the table.

Once a service has been rendered, service providers can also provide other elements that can be hung on an APIs.json, just as with Swagger, and other elements of operations. I am already including references to Postman collections in my APIs.json files, and have begun adding API Science statistics and visualizations as part of regular API indexing details.
![]()
This provides both an inbound opportunity for the delivery of new services, but also the publishing of essential outcomes from those services being delivered, that can benefit API service providers. These details can also provide important elements for other API service providers to use. Imagine if API providers like API Change Log could pull in API Science and Runscope details to enhance and augment their own services, providing more details about the availability of services, and the changes that have occurred–then API Change Log can publish their own results, further enriching the index for each API.
![]()
This opens up a community effect, when it comes to delivering vital services throughout an API life cycle. As an API provider I do not have to do everything myself. I can design, deploy, and management my APIs, then allow service providers to index my APIs.json, and demonstrate the value their services deliver, and then choose which services I need–making the API life cycle a more community driven affair, opening the door up to a wealth of potential APIs.json driven services.
API Testing
API Monitoring
API Discovery
API Performance
API Proxy
API Cache
API Performance
API Visualization
API Dictionary
As an API provider I do not have time to do everything, and many of the API service providers out there need valuable meta data about API operations to offer, enhance, and evolve their service offerings. I can take these services and improve my API operations, no matter where these APIs exist, publicly or privately–all I need is an APIs.json file as the seed. All of this moves APIs.json well beyond just discovery, and like Swagger provides a central truth for not just defining the API, but defining entire API operations.
![]()
We still have a long way to go, before all aspects of API operations are machine readable, but APIs.json can be used today for indexing of the technical side of operations, and with the help of API definition formats like Swagger and API Blueprint, these elements of operations, can be read, imported, and acted upon programmatically both other systems. Since all of my APIs, now live in their own Github repositories, with APIs.json as a central index, pull requests can be made adding elements to the index, potentially by 3rd parties–further making the API life cycle a community effort.
![]()
Swagger and API Blueprint have solidly moved beyond an interesting new advancement of the API space, they are being used by start ups, small businesses, enterprise groups, and even government agencies to define the technical side of API operations. When bundled with APIs.json, we can build a machine readable bridge to the other aspects of API operations, like the business side.
![]()
Swagger and API Blueprint both started by providing interactive API documentation, an essential building block for on-boarding API consumers, which is more about API business, then the technical details. These API definition are now moving into other business areas like delivering how-two materials, potentially driving pricing, dashboard elements, or other embeddable elements that can be used across API operations.
![]()
With the introduction of machine readable API licensing formats like API Commons, the legal, or as I call it, the political aspects of API operations comes into play as well. I am using APIs.json to connect the service composition, tiers, and rate limits, to the technical, and business details that are indexed in an APIs.json file. This is just the beginning, soon other aspects like terms of service, patents, and deprecation policies can also be included, further expanding the APIs.json index of each API, and the collections of APIs.
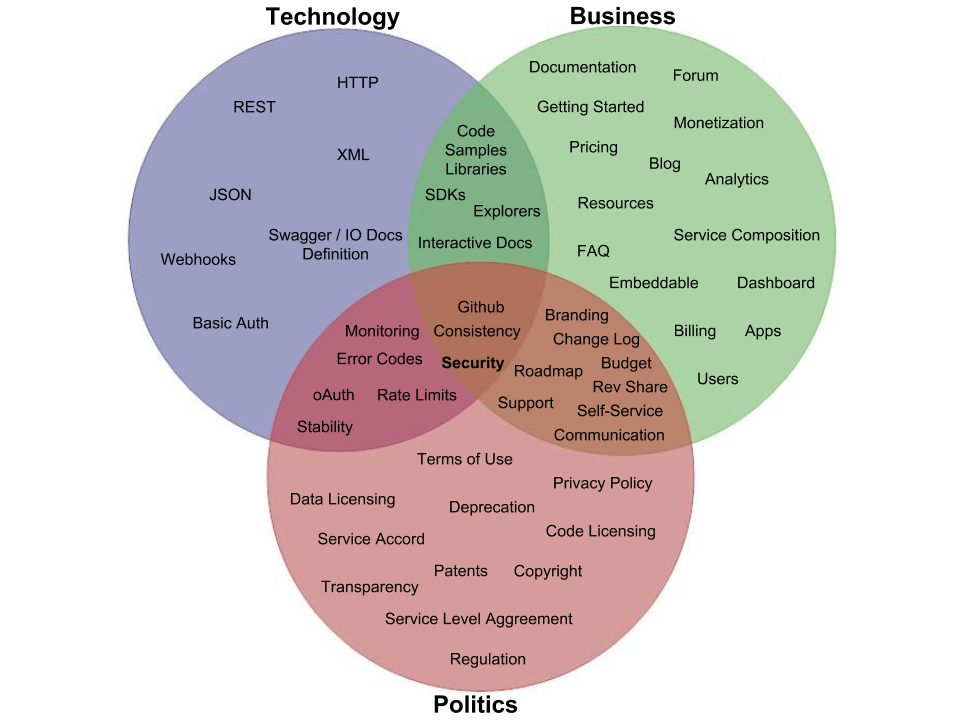
This is a story of my own infrastructure, but is derived from the research I do across the API space. I work hard to not be just an API pundit, and actually practice what I preach. I’m slowly moving from the academic version of this, to a fully functional version, that is my own architecture that I use to run the API Evangelist network.
I gave a version of this talk last night at 3Scale offices, and will be giving various versions of it at APIDays Mediterranea this coming week in Barcelona, and again at Gluecon in Colorado, on May 20th. Over the summer I will continue to evolve my architecture for both Kin Lane and API Evangelist, and evolve a new set of stories, and talks that I can give, helping me share my approach.
I will publish the slide deck of each talk that I give at APIDays and Gluecon on my Github repo when ready, for everyone to reference. Thanks for paying attention.
Disclosure: 3Scale and WSO2 are both API Evangelist Partners

