I have been spending time thinking about how we can build in fault tolerance, and change resiliency into our API SDKs, and client code. I want to better understand what is necessary to develop the best possible integrations as possible. While doing my regular monitoring this week I came across a Tweet from @Runscope, with a pretty interesting image on this subject crafted by @realm, a mobile platform for sync.
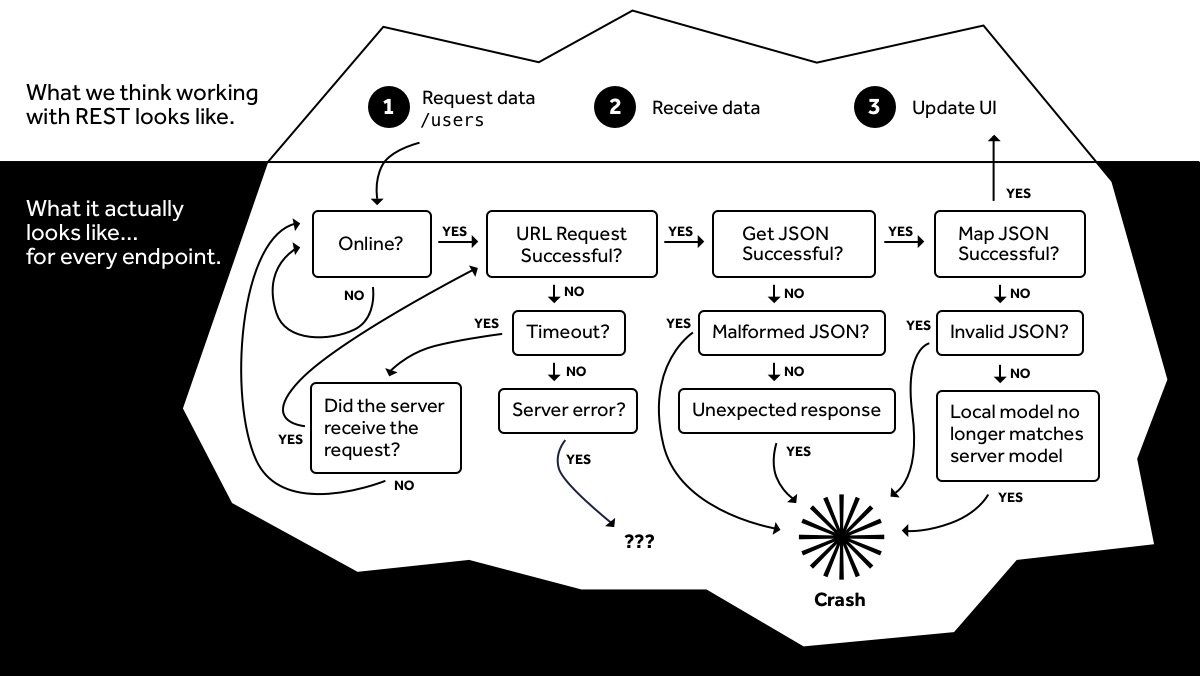
There is a wealth of building blocks here to apply at the client and SDK level, helping us achieve more fault tolerance, and make our applications, systems, and device integrations more change resilient. I wanted to break them out, providing a bulleted list I could include in my research:
![]()
- Is the API Online?
- Did the server receive the request?
- Was URL request successful?
- Did the request timeout?
- Was there a server error?
- Was JSON receive successfully?
- Was JSON malformed?
- Was there an unexpected response?
- Were we able to map to JSON successfully?
- Is the JSON valid?
- Does local model match server model?
There are some valuable nuggets present in this diagram. It should be crafted into some sort of algorithmic template that developers can apply when developing their API integrations, as well as for API providers when developing the SDK and client solutions they make available to their API communities. I’m taking note so that next time I spend some cycles on my API SDK research I can help solidify my own definition.
This is a very micro look at fault-tolerance when it comes to API integration, and I’m continuing to look for other examples of change resiliency at this layer. Meaning, is there a plan B for the API call? Is there revenue ceiling considerations? Or other more non-technical, business and political considerations that should be baked into the code as well. Helping us all think more deeply around how we encourage change resiliency across the API community.
