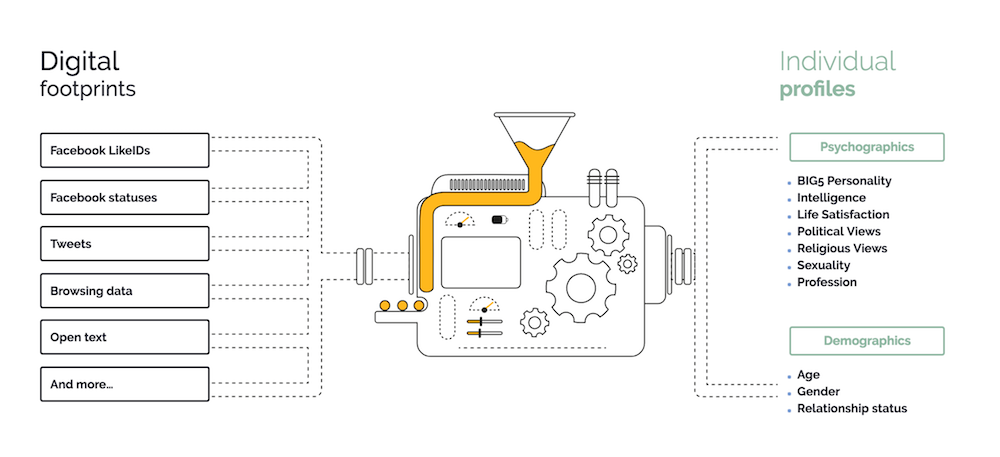
I was doing some research into what was going on with the API landscape at universities and I came across the Trait Prediction API from the University of Cambridge. I’m still studying what they have going on from a social API perspective, but I thought their approach to API ethics stood out as something I wanted to explore some more.
The University of Cambridge, “encourage all of our collaborators to adhere to the following ethical principles, in addition to the applicable legal restrictions”:
- Control: Nobody should have predictions made about them without their prior informed consent
- Transparency: The results of any predictions should be shared with individuals in a clear and understandable format
- Benefit: Predictions should be used to improve services and provide a clear benefit to users
- Relevance: It should be clear why the data requested is relevant to the prediction being made
I do not have formal areas of my API research dedicated to API ethics, but I think I just found my first couple of building blocks to add to it when I do fire it up. I’m seeing more discussion of ethics in computing going on in this era of artificial intelligence, machine learning, big data, and surveillance capitalism. It is a conversation I want to help encourage, by finding examples of ethics being injected into the API lifecycle, either at the provider or the consumer level.
With our current track record when it comes to ethics and technology, I’m thinking we are going to need plenty of examples in the future of ethics being a priority, to help shine a light on. Providing clear examples of how to do technology without exploiting and screwing people over, which many people seem to not get.

