I have been working on the next version of the Human Services Data API (HSDA) OpenAPI lately, taking all the comments from the Github repository, and pushing forward the specification as far as I can with the minor v1.2 release. I have the Github issues organized by v1.2, and have invested time moving forward the OpenAPI for the project, as well as my demo site for the effort.
With this release I am focusing on six main areas, based upon feedback from the group, and what makes sense to move forward without any non-breaking changes:
- /complete - add an /everything to each core resource, allowing access to all sub resouces.
- query - Shifting query parameter to be array, allowing for multiple fields to be queried.
- content negotiation - Allow for JSON, XML, and responses.
- sorting - Adding sorting.
- pagination - Adding pagination.
- status codes - Add more status codes.
These were main concerns regarding what was missing from the last release, and were the top items that made sense to push forward this round. I’ve made some other major shifts to the project, but before I go through those, I wanted to provide some more insight into these v1.2 changes to the core HSDA specification. Helping shed some light on why I did what I did, while I am looking to make the API interface as usable as possible for HSDA implementations, vendors servicing the space, as well as developers looking to build web, mobile, voice, and other applications on top of any APIs that support the implementation.
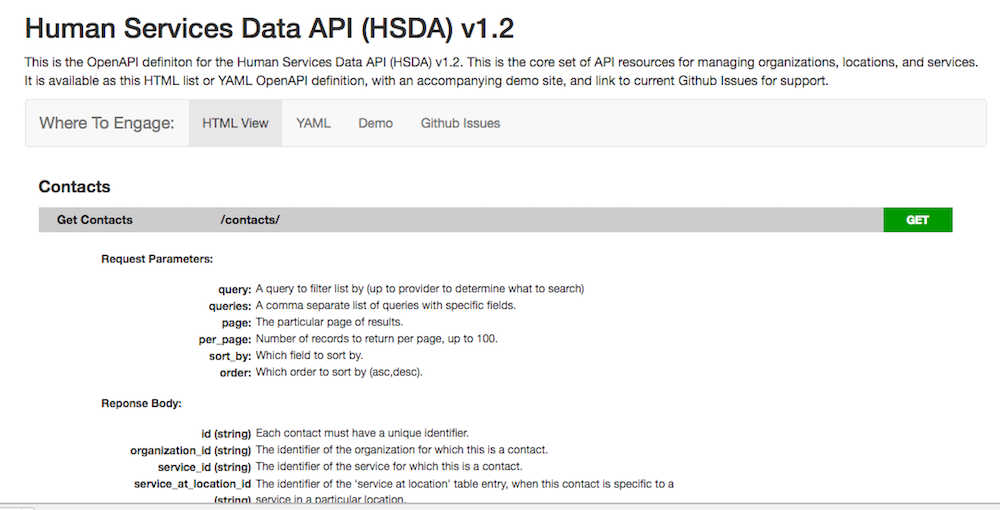
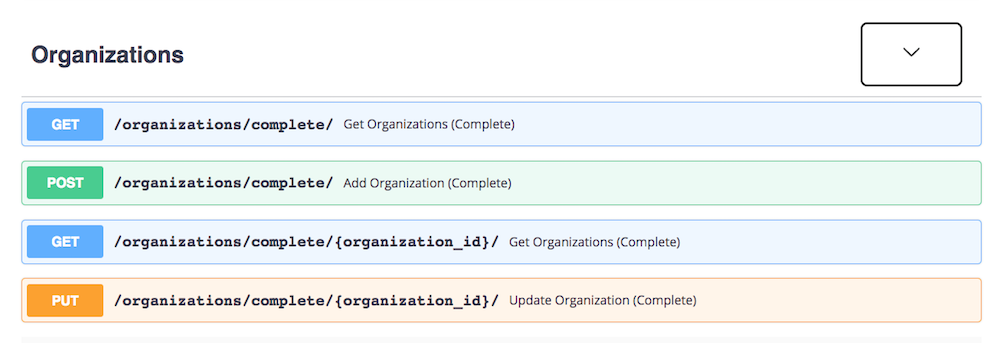
Complete Getting access to the entire surface area of the core resources (organizations, locations, and services), as well as all the subresources (phones, physical address, mailing address, etc.) was the most voiced request from v1.1. I had laid out several options to access the entire surface are of HSDA resources, but folks seem focused on a single set of API paths to accomplish what they needed from a vendor and implementation perspective. It is my job to keep the API serving all types of integrations and use cases, but definitely couldn’t ignore providing a single set of paths for GET, POST, and PUT of organizations, locations, and services.
It was important to me to keep the core resources accessible as a flat, one dimensional, and machine readable documentation, so API consumers could quickly import into spreadsheets as CSV, or make lists of addresses, or possible lookups and updates to a single phone number. I didn’t want to abandon these use cases, or introduce breaking changes, so I introduced a /complete path for all three of the core sources (organizations, locations, and services. These paths allow for GET, POST, and PUT requests of multi-dimensional JSON objects, access the core, as well as sub-resources for any data stored within the API. These paths should accommodate the heavy system to system vendor and implementation usage that was voiced as part of the feedback process, while still preserving other individual use cases.
Query With v1.1 the query parameter for making API requests on organizations, locations, and services was simply a string, which you could provide a set of strings for. At the request of the community we’ve made this an array, allowing you to specify multiple fields and values as part of your query. To ensure I didn’t introduce a breaking change, I did not alter the existing query parameter, instead I added a new parameter called queries, which allows you to get more detailed with your queries. Now there is a simple search, and more robust multi-field search, giving more control to API consumers. In the future we will explore more query power, but this might reside in the search API portion of this conversation which we’ll address later.
Content Negotiation The Human Services Data Specification (HSDS) is a CSV format. While HSDA has focused on using JSON as part of all API requests and responses, I made sure that v1.1 stayed true to the original HSDS format, making the entire surface area accessible via simple API paths, and returning one dimensional responses that can still be returned as CSV. So with v1.2 I allowed for the negotiation of either CSV, XML, or JSON content types for all the primary HSDA paths. The /complete paths do not support CSV, as they provide access to resources, and sub-resources that cannot be returned as CSV, but the rest of the surface allows API consumers to negotiate the format they desire.
Keeping the surface area of the entire HSDS format accessible via simple API paths, without authentication, and providing the option of returning data in CSV, opens up the API to be used to export to Excel and Google docs in a single step. This will open up the ability to extract core resources like organizations, locations, services, as well as sub-resources such as phone and address lists into CSV format, which can then easily be used by a much wider audience than just developers, and other common API consumers.
Sorting There was no ability to sort any data within an HSDA responses with previous version. With version 1.2 you can now provide a sort_by parameter which determines the field to sort by, and order, which determines whether to sort by ascending (asc), or descending (desc) order. I had in there to add the ability to sort by what has been changed recently, but I have run out of time, and will make sure it gets into future releases. It was important that we at least get basic sorting features in there for this release, and can add more aspects to this dimension in the near future.
Pagination In previous versions of HSDA you could pass in a parameter to specify which page to return, and per_page to determine how many results to return per page. However, there was no data return telling you which page you were on, the count per page, or anything else about what is next or previous as part of each results. Several solutions to this were presented as part of the feedback process for v1.0 and v1.1, but not much feedback was given on the subject. Again, I was looking to introduce this feature without any breaking changes. With the flat, one dimensional array structure of the HSDA response structure it would be difficult to add in any envelope, or collection for returning pagination data, so I set out to find examples of how it can be done without disrupting the current response structure.
After looking at Github an a handful of other approaches I opted to add a customer header called x-pagination which provides a JSON object containing total_pages, first_page, last_page, previous_page, and next_page to each GET response, allowing consumers to easily navigation the pagination for large API responses. This approach does not introduce any breaking changes, while still providing all the data needed by API consumers to navigate the surface area of any HSDA implementation, across organizations, locations, and services. I do have some concerns about developers being HTTP header aware, and know how to access headers, but it is something that with a little bit of education, can open a whole new world to them–something any API developer should have in their toolbox.
Status Codes One area that HSDA v1.0 and 1.1 were deficient in was when it came to HTTP status code guidance. I had this slated for v1.3, but I was needing to know when I hit an error in some of the validation, documentation, and other tooling had been working on. So I took this opportunity to add 403, and 500 HTTP status codes to all API responses. All the GET paths are publicly available, but with this edition I’ve introduced an API management service, allowing me to secure all POST, PUT, and DELETE paths, opening them up to multiple users in a secure way. I didn’t want all other users to simply get a 404, so I added 403 guidance. I will be adding more specific HTTP status code guidance, and error response schema in future versions.
Additional Services That was the majority of features involved with the v1.2 release. However there were other aspects of HSDA that were left out of v1.1, like meta, search, and taxonomy. Also, as part of the v1.1 feedback process there were other features thrown out that were needed as part of future releases. All of this had the potential to add unnecessary complexity to the core set of resources, making the specification bloated, making things even more complex than it already is. To help alleviate these challenges I’ve started breaking future APIs into separate projects, or services. Here are the additional seven services I’ve added:
- HSDA Search - A service dedicated to search across HSDA implementations.
- HSDA Bulk - A service dedicated to managing bulk operations across HSDA implementations.
- HSDA Taxonomy - A service dedicated to working with taxonomy across HSDA implementations.
- HSDA Orchestration - A service dedicated to handling orchestration, evented infrastructure, and webhooks across HSDA implementations.
- HSDA Meta - A service dedicated to handling meta data and logging across HSDA implementations.
- HSDA Management - A service dedicated to introducing an API management across HSDA implementations.
- HSDA Utility - A service dedicated to housing all utility APIs across HSDA implementations.
All of these services are meant to augment and complement the core set of HSDA resources, and sub-resources without adding unnecessary complexity to them. These projects are meant to act as a buffet of services that human service providers can choose from, or they can opt to just stick with the basic. I’ve reset the version for each of these projects to v1.0, and will be moving them forward at their own pace, independent of what the core HSDA specification is doing. I’ve introduced separate OpenAPI definitions for each project, and I am pushing forward independent code repositories for delivering PHP/MySQL implementations for each service area. Like the other features for HSDA v1.2 above, I wanted to take a moment and explain the logic behind each of these services.
HSDA Search Early on in the release of v1.1 the question of search quickly began to muddy the conversation. I saw this was going to be a challenge. I saw the communities desire to deliver features via query parameters, and knew that search was going to introduce a number of parameters beyond what was needed to just manage core resources (organizations, locations, and services). We also started getting some great feedback from vendors in the Github issues for search features that went well beyond what was needed for individual resources, and often spanned all the core resources. Search had been a separate path in the core HSDA specification, and with this version I decided to break it off the core specification and put it into it’s own project, where it can become a first class citizen.
The current HSDA search v1.0 specification got all query, queries, sorting, and pagination that the core HSDA resource received in the v1.2 release, but once they were added it got broken off into it’s own service. Technically this is a breaking change, but I think it is one the community will support, as it will add some valuable search features. Immediately, I added a set of collections that spanned all core resources, including organizations, locations, and services, and I took the /complete features I had just added to HSDA and introduced them to HSDA search. This makes all the search results as rich, and complete as possible, providing access to the entire surface area. I feel like ultimately this is where we will be experimenting with allowing consumers to restrict, or expand the results they are looking to get back, while keeping core resources cachable, available at known paths.
HSDA Bulk One of the conversations that led to the introduction of /complete paths for all core resources in v1.2 was the needs of vendors, and the heavy lifting requirements of individual implementations. There was the need to load large volumes of data into systems, as well as between disparate systems. There was talk about the load this causes of systems that drive critical websites and other infrastructure, resulting it being something done during off-peak hours. Some of this work can be done via the primary HSDA /complete service, but it was clear that a separate bulk set of API would be needed to help handle the load, and meet the unique needs of system integrators, that were different than what web, mobile, voice, and other applications developers would be building.
HSDA Bulk reflects the HSDA /complete paths for organizations, locations, and services, but these paths accept the posting of arrays of objects, complete with all their sub-object. Instead of directly loading these into the main database upon POSTing, they are entered individually into a jobs database, where they can be queried, and run independently on a schedule, or based upon specific events. HSDA bulk will work in conjunction with HSDA, HSDA Meta, HSDA Management, and HSDA orchestration, or it can be run independently, based upon custom criteria. The goal is to provide a way to handle the bulk needs of HSDA implementations which can be deployed, scaled, and operated independently of any core HSDA implementation, limiting the impact on core websites, mobile applications, and other applications.
HSDA Taxonomy The taxonomy portion of HSDA got separated as part of the v1.1 release. I quickly saw it needed more thinking regarding the handling of multiple taxonomies, as well as allowing for the accessing of services beyond core HSDA resource management, or even search. HSDA Taxonomy is now it’s own project, and can be deployed independently of any HSDA implementation, but provide another doorway for querying, browsing and getting at services based upon any supported taxonomy. The v1.0 version of HSDA Taxonomy will support AIRS and Open Eligibility, but will be designed to support any other taxonomy, and allow for customization by individual implementations, while maintaining a common API for usage across multiple HSDA implementations.
HSDA Orchestration Throughout HSDA v1.1 discussion I kept hearing about the need for notifying users of changes to HSDA data, and the need to push and ping external systems with information. As part of the build up to v1.2 I conducted a significant amount of research into the event and webhook implementations of leading API providers like Box, Twilio, Stripe, and others. I’ve taken this research and created a v1.0 draft for an HSDA Orchestration solution. Working to alleviate a wide variety of needs for handling events that occur across HSDA implementations, engaging with external implementations, and making HSDA a two-way street.
HSDA Orchestration will potentially work with HSDA Meta, HSDA Bulk, HSDA Management, and of course, HSDA core to bring implementations alive. A number of events will be defined around common HSDA task that occur like POSTing of new organizations, or locations, or updating of individual records, or possibly the submission of bulk updates that need running. Every API call within an HSDA implementation can now be tracked using HSDA Meta, and HSDA Orchestration will monitor this, and allow API consumers to subscribe to these events via webhooks, and receive a ping when event occurs, or receive a fat ping, which pushes data associated with an event to an external URL. HSDA orchestration will handle all the monitoring, tracking, notification, and syncing needed between HSDA implementations via a separate, independent service that works with the HSDA stack.
HSDA Meta HSDA Meta is another feature that got set aside with the v1.1 release. With v1.2 I’ve set it up as it’s own project. Now each API call made to any core HSDA path will be added to the HSDA Meta system, recording the service, path, verb, parameters, and body of each request. HSDA Meta is designed to providing a logging solution, eventually a transactional layer that can be rolled forward or backwards, and is intended as stated before to work with HSDA Bulk, HSDA Orchestration, and leveraging HSDA Management for access, and auditability of all activity.
HSDA Management HSDA is in need of an API management layer. Many of the paths available allow for reading, writing, and deleting of data. The original HSDA v1.0 and v1.1 only allowed for a single administrative key for accessing all POST, PUT, and DELETE API paths. With the v1.2 release I’ve begun this separate project for allowing the adding, authenticating, and managing of API users who are looking to get at HSDA data. The current implementation allows for many users, and each users to have access to one, or many of the services, and supporting API paths. It is up to each implementation to decide which users get access to which. In future releases we will add the notion of access plans, allowing for trusted groups to be established, including partners, and internal consumers. The goal with this is to identify a common interface for HSDA implementations, which behind the scenes could be any number of existing API management implementations.
HSDA Utility Last, I needed a place to put any utility APIs I needed to help manage HSDA implementations. Right now there are two core set of APIs. One for managing which services are available across and HSDA implementation, and another for validating HSDA schema, and eventually the APIs themselves. I will be putting any other utility API within this service area. It will become the catch-all for any API that doesn’t fit into it’s service area.
HSDA Specification That is it. That is the bulk of the work I’ve done for the v1.2 release of HSDA. I’m pretty happy with how things have worked out. I feel there is a lot more coherency across the specification now, and the service mindset will allow for much more constructive conversations across the projects. I have updated the HSDA specification site with all eight of the OpenAPIs, publishing a separate documentation page for each one. Each page provides an HTML view for each service, as well as link to the YAML version of the OpenAPI, the demo website, as well as Github Issues for each project. Next step is to drive the feedback and comments via the Github issues, include anything that is missing, and push v1.2 out the door, and begin working on v1.3, as well as the v1.1 for the seven other projects that were added with this release.
HSDA Implementation I do not ever feel an OpenAPI is ready for prime time until I have a working version of it. I have created working versions of all eight HSDA implementations. The core HSDA is the most complete and robust, with HSDA Search, HSDA Bulk, HSDA Meta, HSDA Management, HSDA Utility, HSDA Taxonomy, and HSDA Orchestration following up in that order. They are v1.0 draft implementations, and for the most part are working, but have not been hardened yet. I would feel comfortable putting HSDA, and HSDA Management, and HSDA Meta into a real world implementation in coming weeks, something I will actually be doing with two separate implementations–using real world projects to harden them.
I have updated the HSDA demo portal to contain all eight projects, and I have leveraged Github authentication as the HSDA Management layer, allowing anyone to signup and use their Github account to access with each API. Each API call is logged, and I can easily revoke access to any account, or push reset on the demo as needed. Now that I have a working copy, I will be publishing a development version of the portal, so that I do not break the demo in the future, and can move forward with releases a little more gracefully than I did with this one. I will be maturing all eight implementations, and offering them up as official Adopta.Agency products for deployment on AWS in the near future.

Looking To The Future This release of HSDA and the supporting code is all about looking towards the future. I’ve separated things out into independent services to handle what is next, and I’ve re-engineered my PHP/MySQL implementations to prepare for the future. Each of the eight solutions are 100% OpenAPI driven. The database and server side code is all OpenAPI driven. The portal, documentation, and the schema validation is all OpenAPI driven. Next, I’m setting up monitoring, and testing, that will all be OpenAPI driven.
I also have two other services I did not include in this story because they are meant for the future. One is HSDA Custom, which allows for the addition of any field, or collection to the core HSDA implementation, accommodating the needs of individual providers. This is only possible because of OpenAPI, and each custom field will be added as x-[field], keeping things validating. The second one I’m calling HSDA Aggregation, which will be my first attempt to sync, aggregate, and migrate data across many HSDA implementations. Now that I have the base, I’m going to setup five separate demo implementations, and begin to work on robust sets of test data, which I can use to push forward an aggregate and federated version of HSDA.
The OpenAPI core for my HSDA work has allowed me to do some interesting things with how the APIs are delivered, as well as many of the supporting tooling. This approach to delivering HSDA implementations can be applied to any API. I will be taking my list of several hundred Schema.org OpenAPIs, and building a catalog of API definitions that can be easily deployed on AWS. I’m not going to do this as an automated software service, but I will be hand deploying solutions for clients using this approach. Providing streamlined, well-defined, yet hand-crafted API implementations for any possible situation. This was born out of hearing from HSDA providers about how they begin storing all types of data into the organizations, locations, and service data stores–things that really should be in a separate system. Eventually I’ll be suggesting other HSDA projects that assist providers with events, messaging, and other common solutions beyond just organizations, locations, and services.
Anyways, that concludes this sprint. I will be doing more work throughout the week, and we have a three day hackathon this week. So I’m looking forward to moving things forward more, but for right now I’m pretty glad with what I’ve achieved.
