I’ve setup a few Lambda scripts from time to time, but haven’t had any dedicated project time to push forward API serverless concepts. Over the weekend I had a chance to deploy a couple of APIs using AWS DynamoDB, Lambda, and API Gateway, lighting up some of the serverless API possibilities in my brain. Like most areas of the tech sector, I think the term is dumb, and there is too much hype, but I think underneath there is some interesting possibilities, at least enough to keep me playing around with things.
Right now my primary API setup is Amazon Aurora (MysQL) backend, with API deployed on EC2, using Slim API framework in PHP. It is clean, simple, and gets the job done. I use 3Scale, or Github for the API management layer. This new approach simplifies some things for me, but definitely goes further down the AWS rabbit hole with the adoption of API Gateway and Lamdba, but also introduces some interesting enough benefits, that has me considering for use on some specific projects.
Identity and Access Management (IAM) Role The first thing you need to do to make the whole AWS thing work is setup a role using AWS IAM. I created a role just for this project, and added CloudWatchFullAccess, AmazonDynamoDBFullAccess, and AWSLambdaDynamoDBExecutionRole. I need this role to handle a bunch of management level things with the database, and logging. IAM is one of the missing aspects of hand crafting my APIs, and is why I am considering adopting on behalf of my customers, to help them get a handle on security.
Simple API Database Backends Using AWS DynamoDB I am a big fan of relational databases, mostly out of habit and experience. A client of mine is fluent in AWS DynamoDB, which is a simple NoSQL solution, so I felt compelled to ensure the backend database for their APIs spoke DynamoDB. It’s a pretty simple database, so I got to work creating an account table, and added a simple JSON object that contained 4 or 5 fields, and fired up an index for the simple accounts database. The databases I’m creating are meant to track aspects of API management, so the tables won’t end up being too large, or have high performance requirements, regardless, DyanamoDB is a perfect backend for APIs, leaving me unsure why I don’t use the platform more often.
Using Lambda Functions Behind The API Instead of firing up an Amazon EC2 and hand crafting my API framework, I crafted a handful of serverless scripts in Node.js that will run as independent Lambda functions. I’m going to eventually need a whole bunch of functions, but to get me going with this new API I crafted four separate Lambda functions that I can use to drive the API:
- searchAccounts - Using the DynamoDB API scan method to query the table.
- addAccount - Using the DynamoDB API putItem method to add a record to the table.
- updateAccount - Using the DynamoDB API udpateItem method to add a record to the table.
- deleteAccount - Using the DynamoDB API deleteItem method to add a record to the table.
Using the AWS SDK, I’m simply making calls to the DynamoDB API to get all the work done. I’m fluent in JavaScript, but not well versed in using Node.js, but it doesn’t take much energy to understand what is going on. The serverless functions are pretty utilitarian, and all that is unique is the DynamoDB method to call, and the JSON that is being sent with each call. It is something that is pretty straightforward, and easily replicated for other APIs. I will keep developing functions for my API, but now I can at least handle the basic CRUD functionality around my new database.
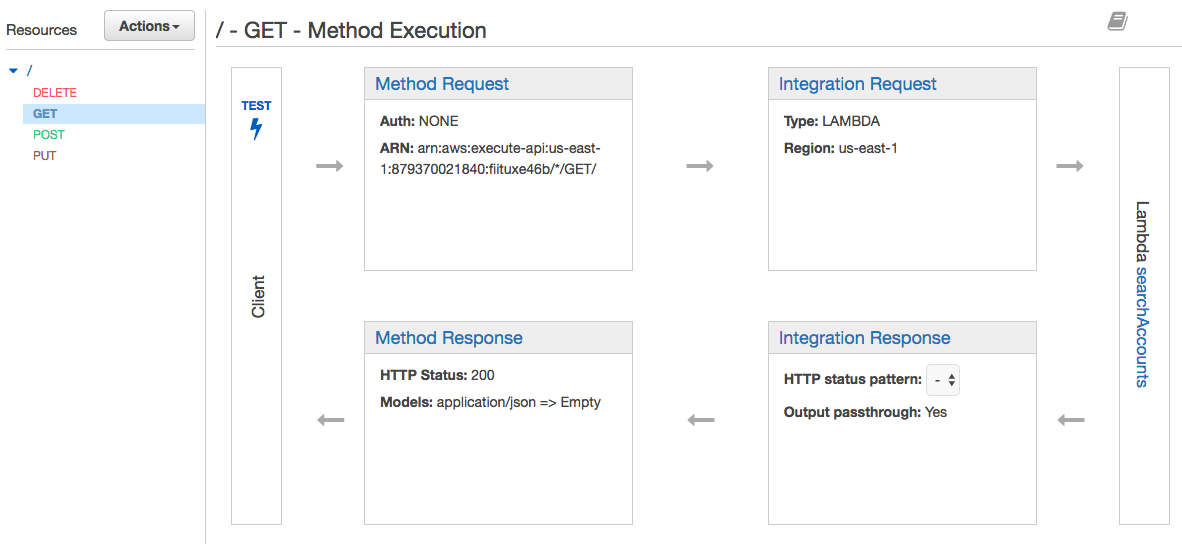
Publish An API Using AWS API Gateway The last piece of the puzzle for this story, is the API. Each Lambda function accepts and returns JSON, which is technically an API, but there is no management layer, or RESTful infrastructure present. The AWS API Gateway gives me the ability to craft API paths, with accompanying GET, POST, PUT, DELETE, and other methods. For each method I add, I’m given four options for connecting to my backend, either via HTTP call, create just a mock API, leverage other AWS service, or connect to a Lambda function. I quickly wire up a GET, POST, PUT, and DELETE to each of my functions, and add my API to an AWS API Gateway plan, requiring API keys, and limiting who can access what.
I now have an accounts API which allows me to add, update, delete, and search for accounts using an API. My data is stored in DynamoDB, and served up via Lambda functions, through the API Gateway. It is secured. It is scalable. I can easily quantify what my database, functions, and gateway resource usage and costs will end up being. I get why folks are interested in serverless. It’s clean. It’s modular. It scales. It is very manageable. I don’t feel like it will be the answer for every API I need to deploy, but it does make sense for quickly deploying APIs for customers who are open to AWS, and need things to be secure, highly performant, and scalable.
A serverless approach definitely takes the sysadmin load off a little bit. Especially when you depend on DynamoDB for the backend. DynamoDB, Lambda, and API Gateway offer a pretty nice stack that can auto tune and scale itself. I’m going to fire up five separate APIs using this new approach, and setup some monitoring and testing to see how it delivers, and maybe get a handle on the costs associated with operating an API like this. I still need to attach a custom domain, get a handle on logging with AWS CloudWatch, and some of the other aspects of API management using AWS API Gateway. However, it provides me with a nice look into the serverless world, and how I can use it to deploy, and manage APIs, but also use APIs to manage a serverless approach by publishing functions using the Lambda API, keeping things in tune with my API definitions stored on Github.
