I am pushing forward how Postman can be used for public data. I have a whole mess of different data sets I need available for different projects I am working on. For one project I am aggregating ten separate environmental data sources available as a mix of CSV, JSON, and excel files, as well as a couple of actual APIs. I am looking to build an embeddable dashboard widget using data across these ten sources, and I am looking to organize all of them via a single public workspace, helping normalize them all as simple APIs returning CSV or JSON. The project is just a POC, and once it moves toward production we’ll launch actual APIs, but for now I am able to mock them using Postman. The process got me thinking about how this approach can be used to make simple public datasets available via forkable Postman collections.
Simple Data APIs Using Collections
As I began aggregating the datasets into Postman, the first couple of datasets were pretty basic. Simple CSV or JSON files, and a couple basic APIs. I just created a collection, added a new request, and pasted the URL into the request and pulled the data from the source.
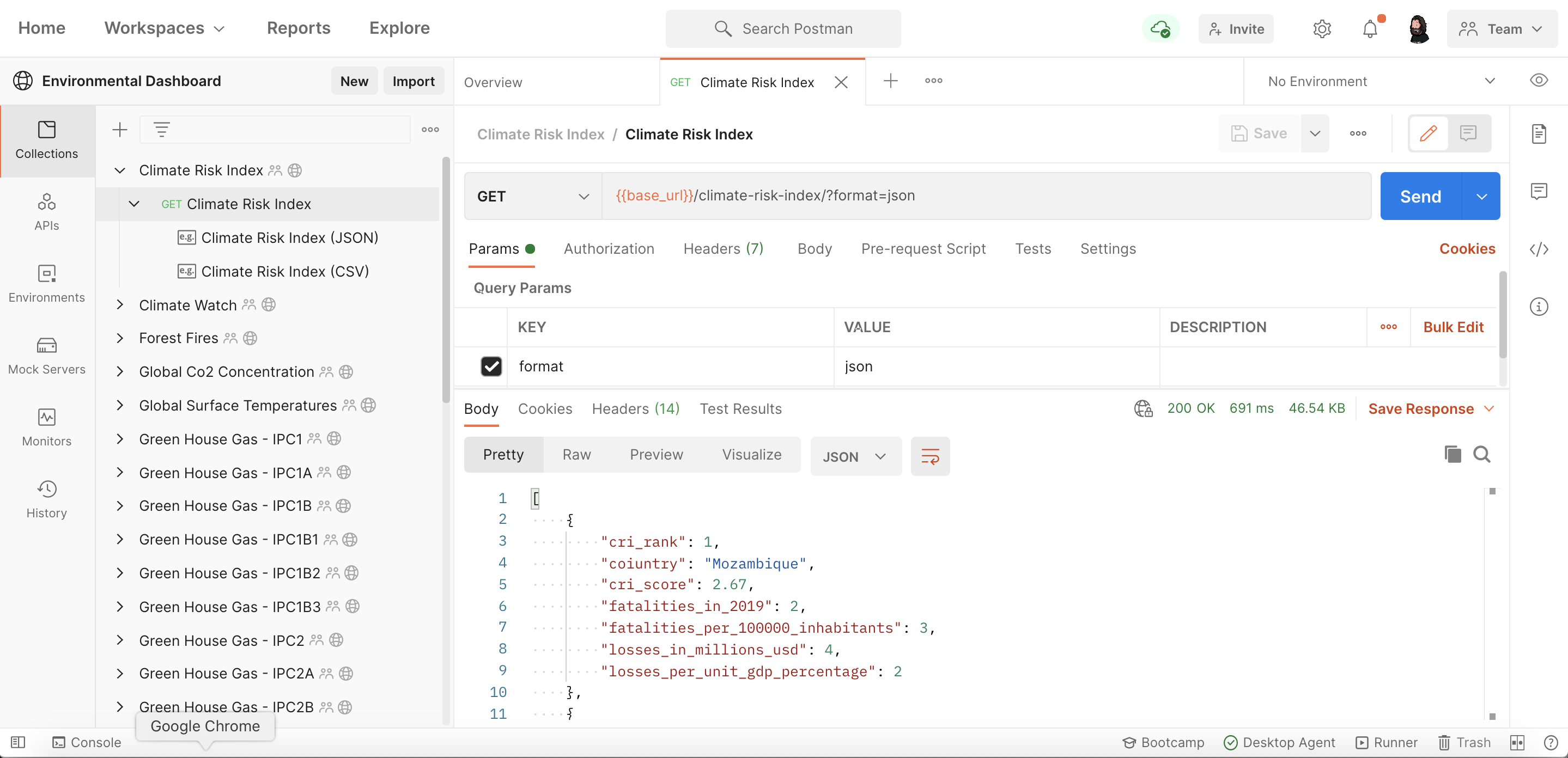
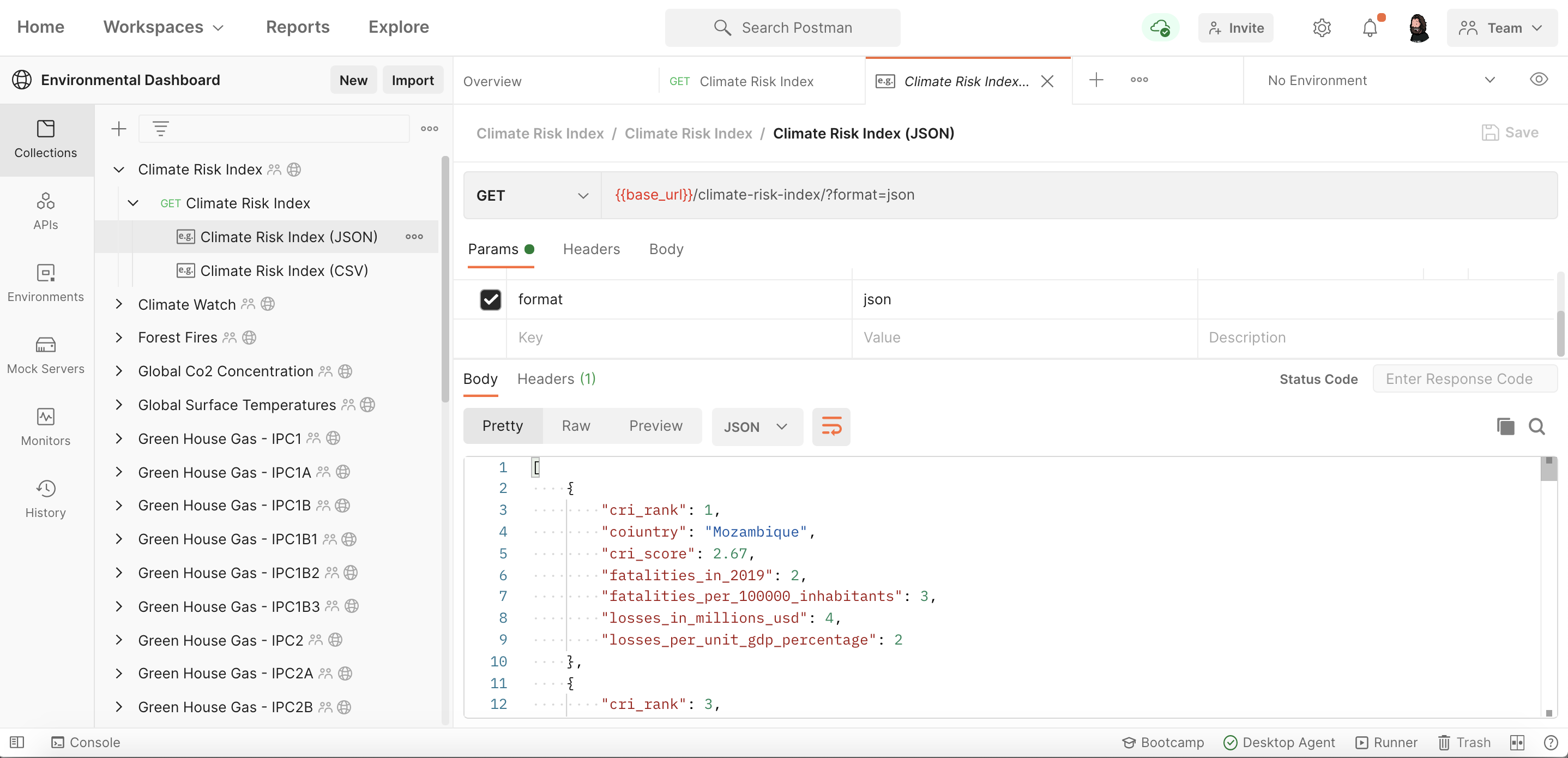
Once I had the response from each API I would save the response as an example for the request. Then the entire CSV or JSON would be stored locally within the collection. For most of them I’d convert the data to, or from JSON or CSV, and add a parameter property so that each response could returned depending on what format the consumer desires for the visualizations.
Now that I have an example stored for each dataset as part of the collection I can mock the collection, making the data available as a simple “mocked” API. This approach provides a public or private URL I can share with anyone who is building a prototype application-—in this case a widget. Going from dataset to a simple API in just a few clicks.
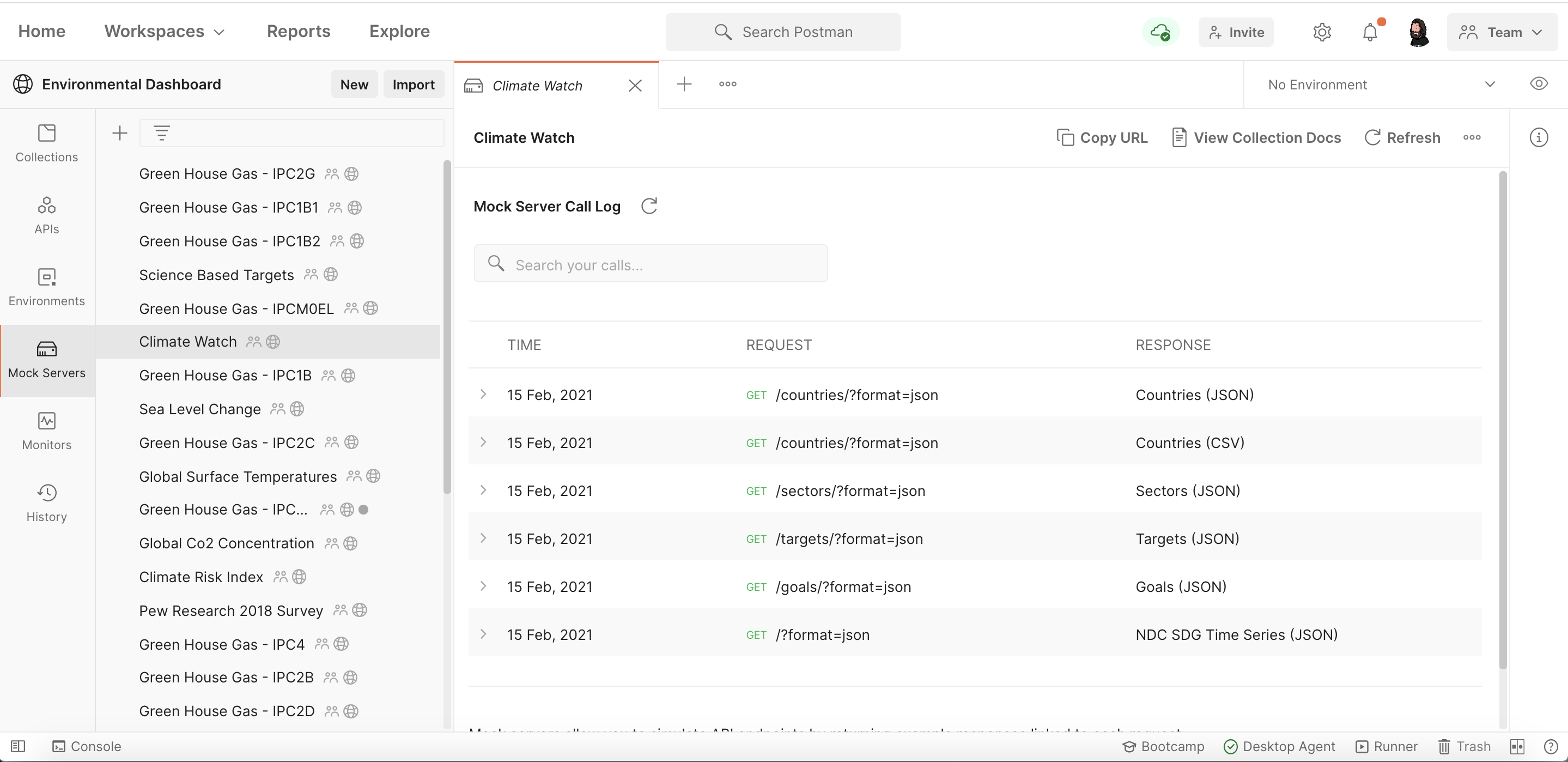
Each of these mock servers are rate limited so I don’t want to share with anyone who will create a lot of traffic, but for low volume design and development it works just fine. Also, anyone can fork the collections, publish their own mock servers within their own accounts—-pulling a fresh copy of the dataset whenever it gets updated. Localizing the mock servers so that they can do what they want with the data and put data to use within their own workspaces.
Sharding Larger Datasets as Collections
After working through a couple of the datasets I came across a couple pretty large ones that were to big to publish as a single request example, pushing me to find another way by sharding the data on top level data points. Properties like year, month, and categories make for good sharding targets, which I make available as separate requests within a single collection.
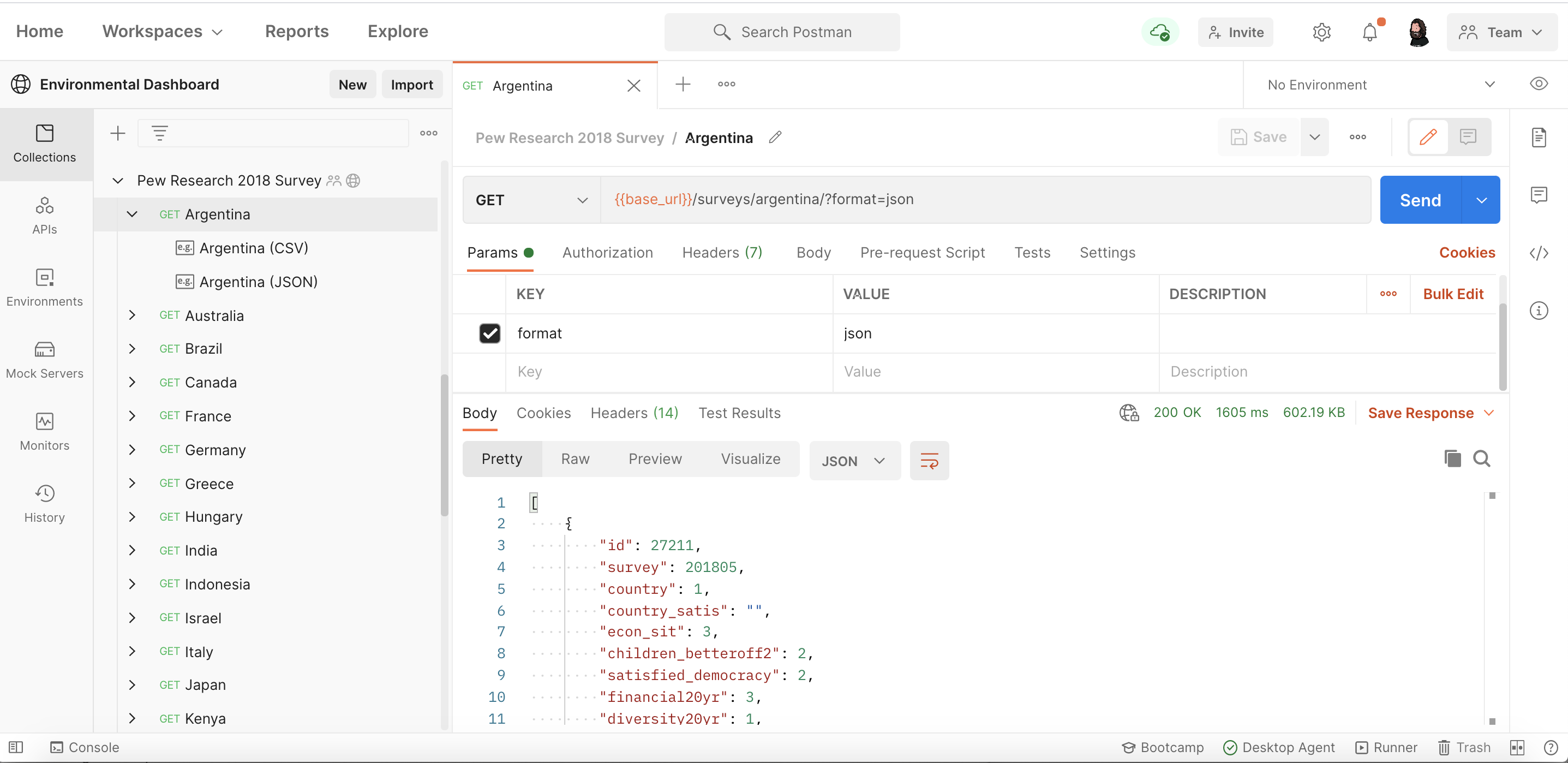
If a dataset is large enough or works better as separate collections I would also break things up as completely separate collections. Allowing them to be organized via a public workspace or embedded as Run in Postman buttons on any website or documentation.
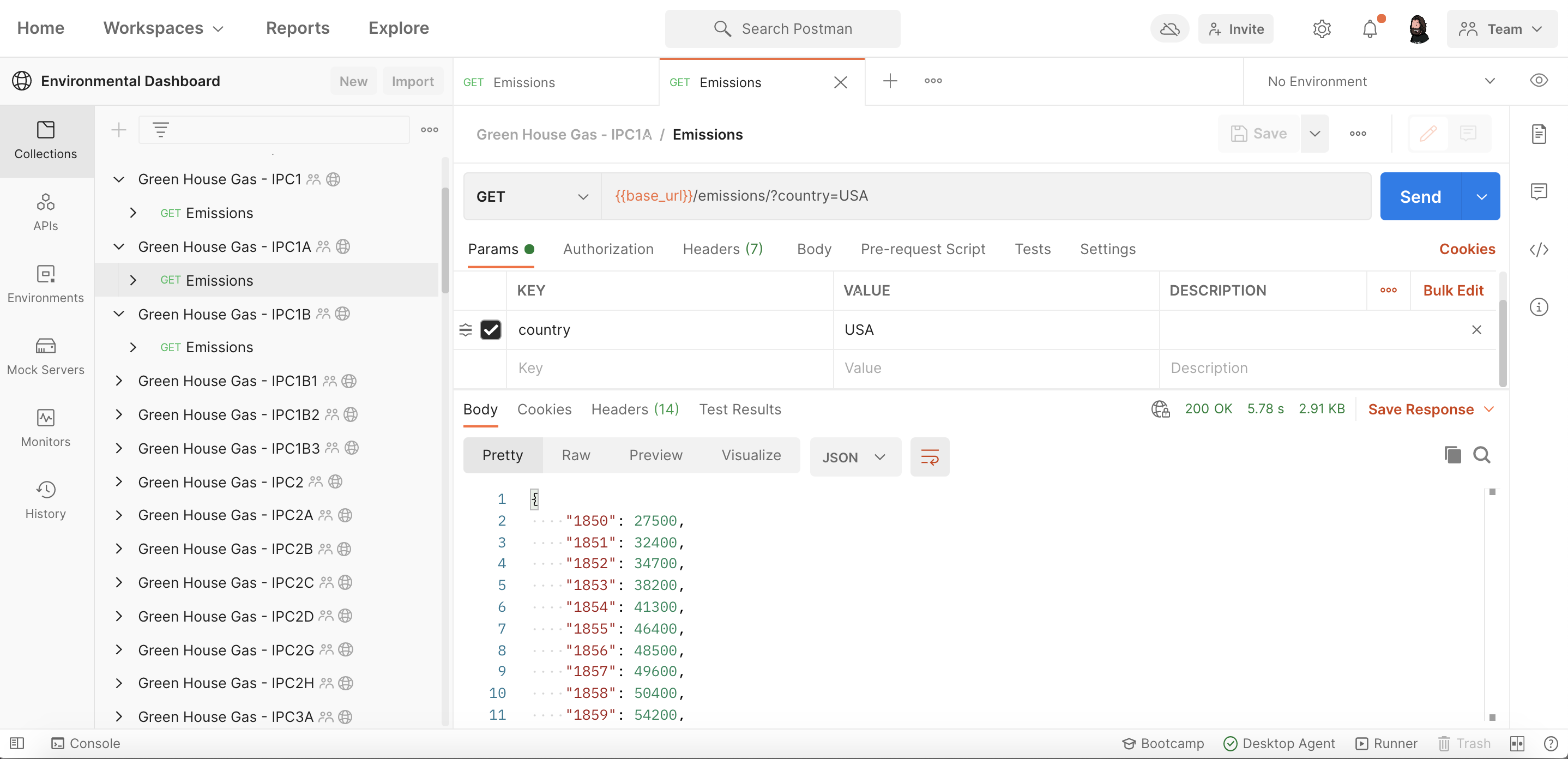
Like the simple datasets, these larger ones can be mocked and accessed via the mock endpoint or it can be forked by users and then mocked and access via endpoints under their own accounts—-pulling updates from the master whenever changes occur.
A Simple Way to Make Public Data Available
I definitely found the limitations of storing data within Postman as examples. I wish Postman had a more robust data store layer behind APIs, and I wish you could publish mock servers with higher rate limits or a little bit of API management built in, but I have what I have. I actually like having constraints because it makes me think about things differently. It reminds me of how I have bent and pushed the boundaries on Github for the last five years, but more tailored specifically to APIs. I am going to work on some tooling for helping do this more efficiently now that I have the concept fleshed out. The approach won’t work for all types of datasets, but certain types of applications it will provide a very low cost and light weight way of publishing public data.
The beauty of this approach is that I can automate it using the Postman API, and like Github I can publish as many workspaces and collections as I need via my Postman team account. I am on the business tier, but really there aren’t any limitations if I am making my collections available via public workspaces. If there are limitations I will quickly figure them out like I did the size limitation on examples and collections, and either decide to push on the Postman road map with feature suggestion or develop ways around the limitations–i like the latter. It really is a game that I like playing, figuring out what is possible, and what isn’t. I am looking to try and see how I can make Postman work in service of public data. The Postman platform is great for publishing and consuming APIs, and I am looking to make sure this includes the publishing and consuming of useful public data.

