
I have a lot of work to do profiling APIs using APIs.json. I am interested in producing as complete an accurate APIs.json for an API provider as I possibly can. When it comes to profiling providers like Amazon Web Services (AWS), this means there are over 350 individual APIs. It isn’t enough that I have a name, description, and tags for each API, but I also want OpenAPI and other properties defined for each one. AWS is pretty formulaic in how they approach their operations, but there is some nuance to each one that takes a balanced approach to profiling.
I am looking for that fine balance between hand-curated and automation. I am looking at streamlining how I profile APIs using APIs.json, but also making sure they are simple, high quality, and possess the API level, but also common API provider level properties. To help document my approach, here is a look at the tool and process I’ve developed to flesh out the API operations for an API provider. Right now I am working on Amazon EventBridge, which I start with a name, rough description, and url to the site.
Once I have the seed of an APIs.json, I click on the strip HTML function I have, and it will clean up the rough description that I have harvested for the API from whatever page I have bookmarked.
Next I click on my “write” function, which will take what information I have for an API and pass it to ChatGPT and ask it to rewrite it for me into something that is a little more readable and coherent (hopefully).
Now that I have the description cleaned I want to expand beyond the properties I have for each API beyond the URL to the documentation page, and the OpenAPI I generated from the AWS SDK manifest.
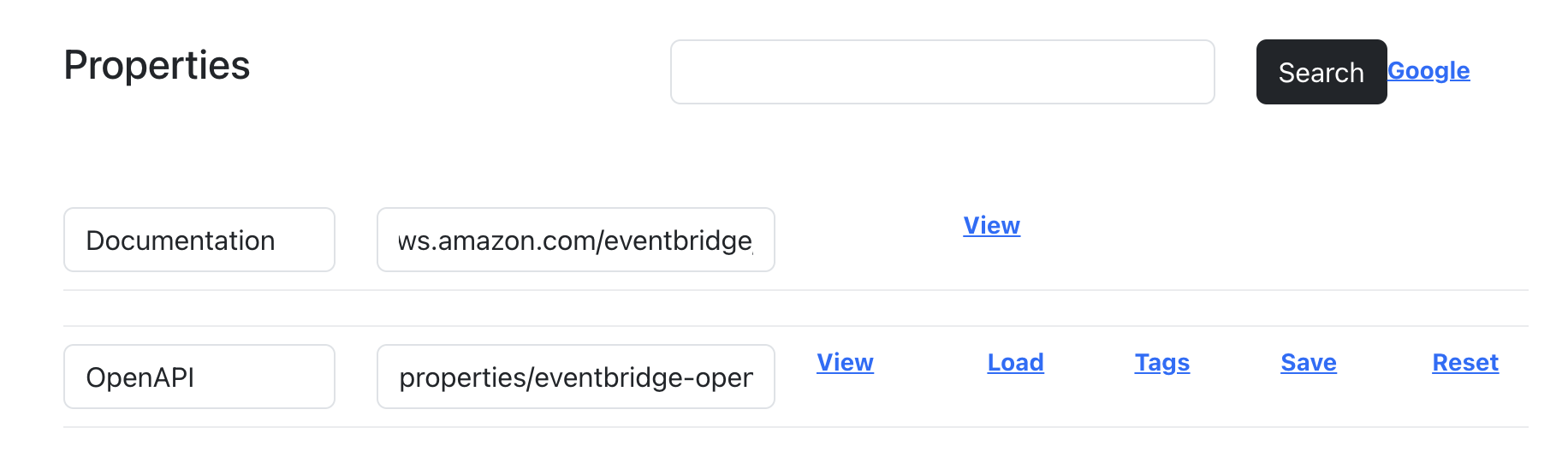
I added a search box with a button and wired it up to the Bing web search API to look for pages related to whatever API I am profiling at the time, giving me a list of properties that I can add to my API metadata.
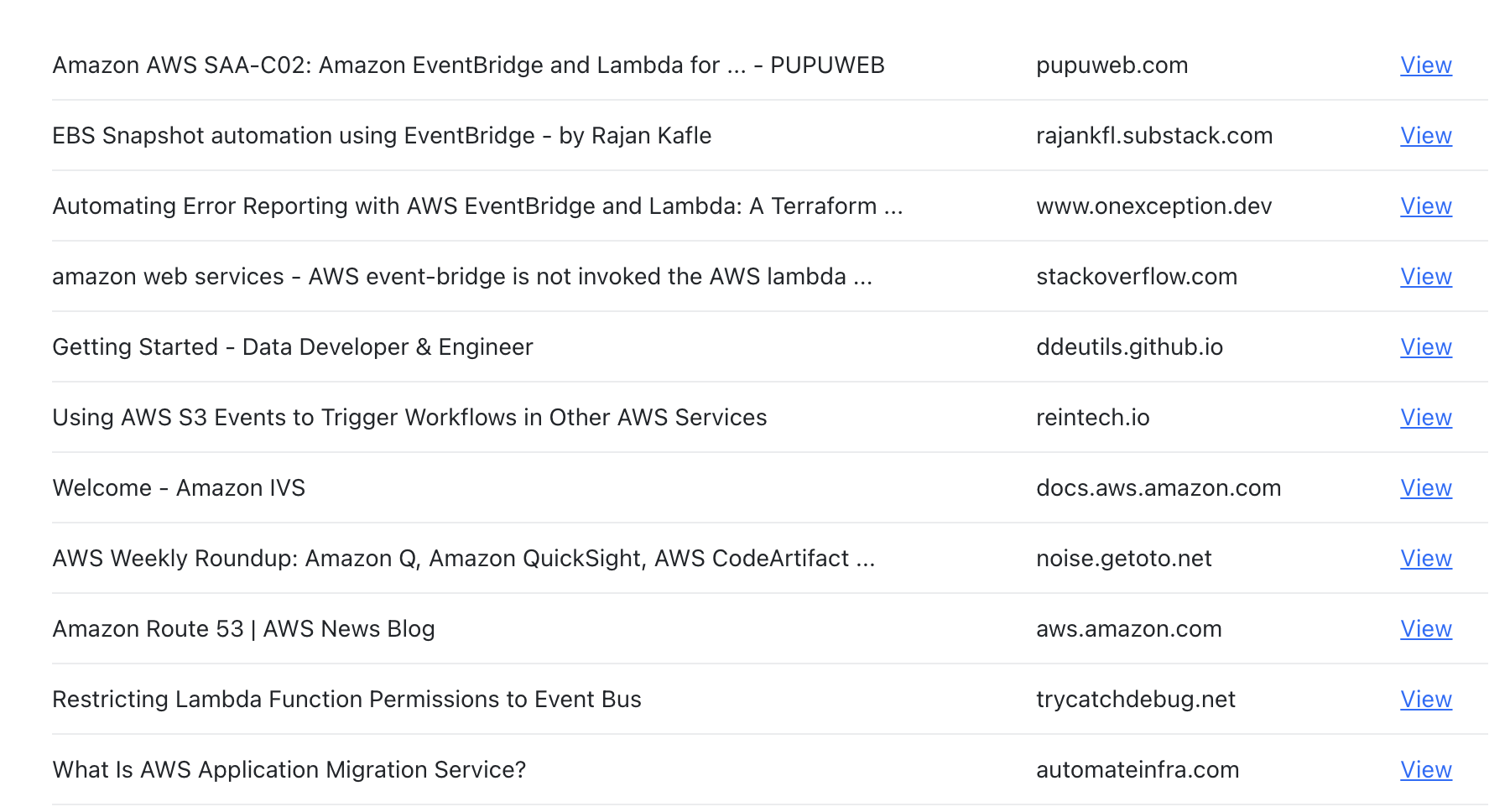
Honestly, the Bing Search results leave quite a bit to be desired which is why I have a Google link next to the button, and I’ll probably wire up another search API, but my plan B right now is to just “harvest” URLs from the documentation page.
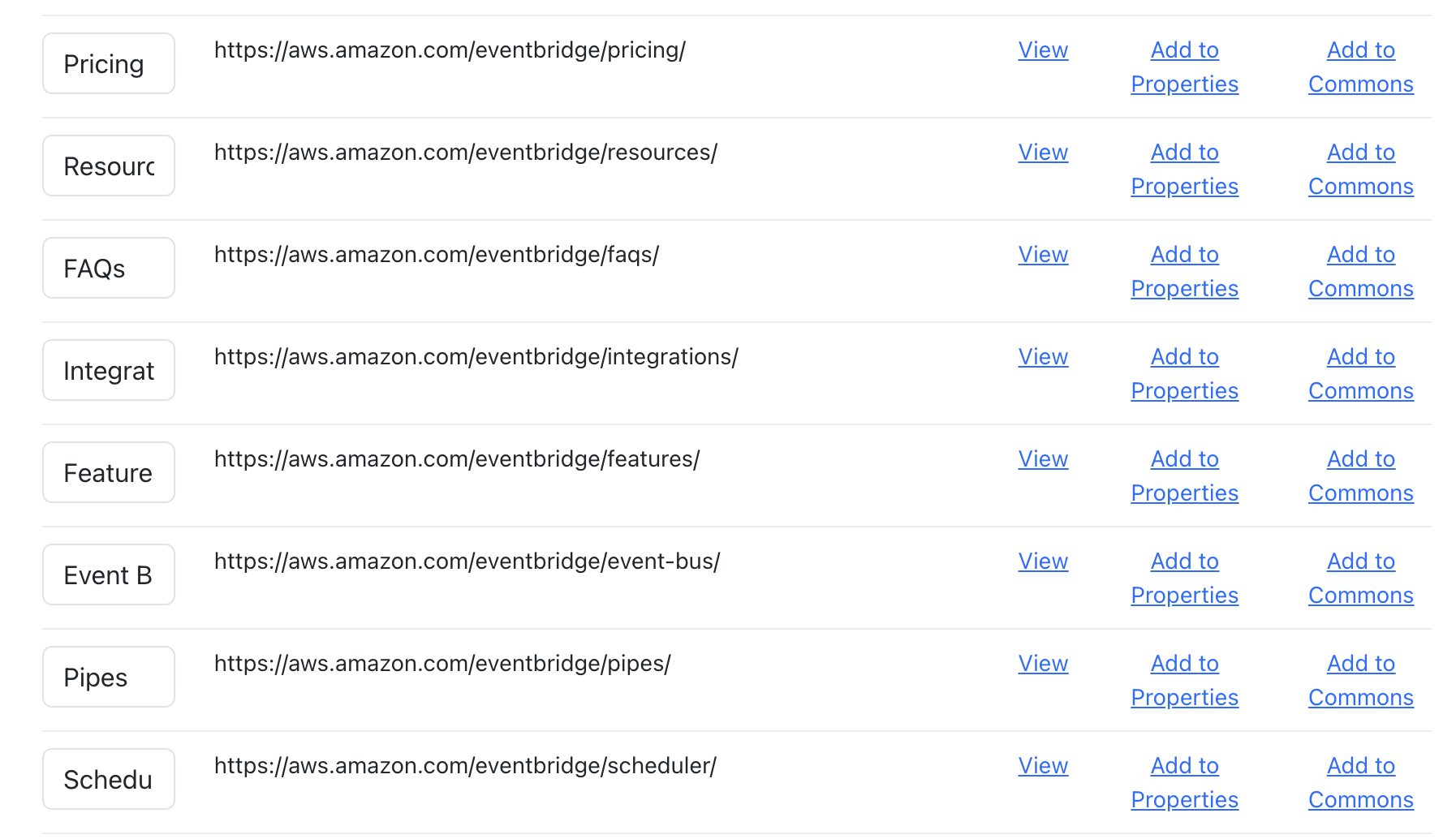
These give me all the individual API level properties for each API, further fleshing what resources are available beyond docs and OpenAPI—not all APIs have individual properties, but others have unique properties available for each API.
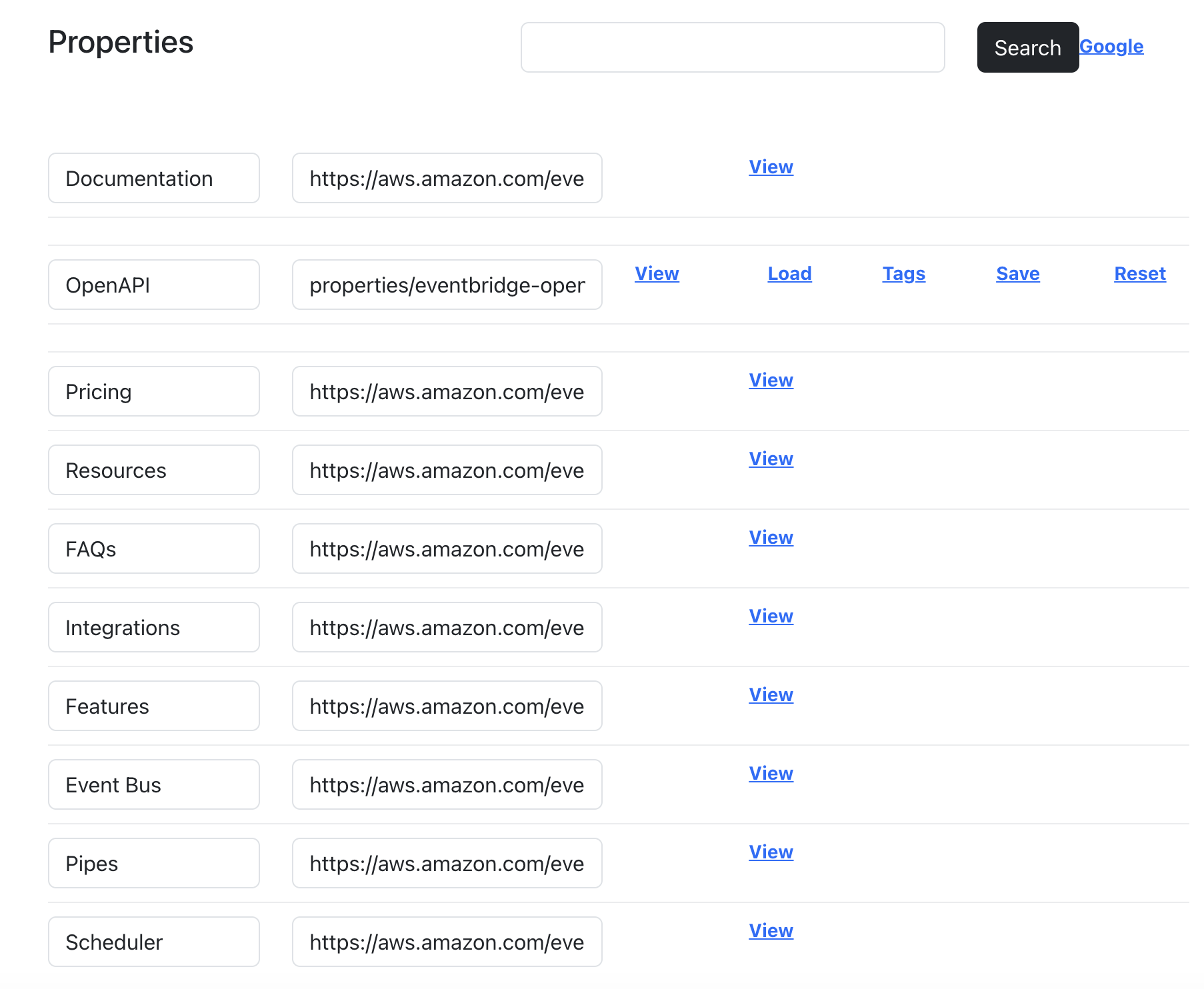
Once I’ve exhausted searching for other API properties I get to work on the OpenAPI itself, pulling the YAML or JSON OpenAPI (if it exists), and parsing each path, method, and operation to further flesh out the details to include in search.
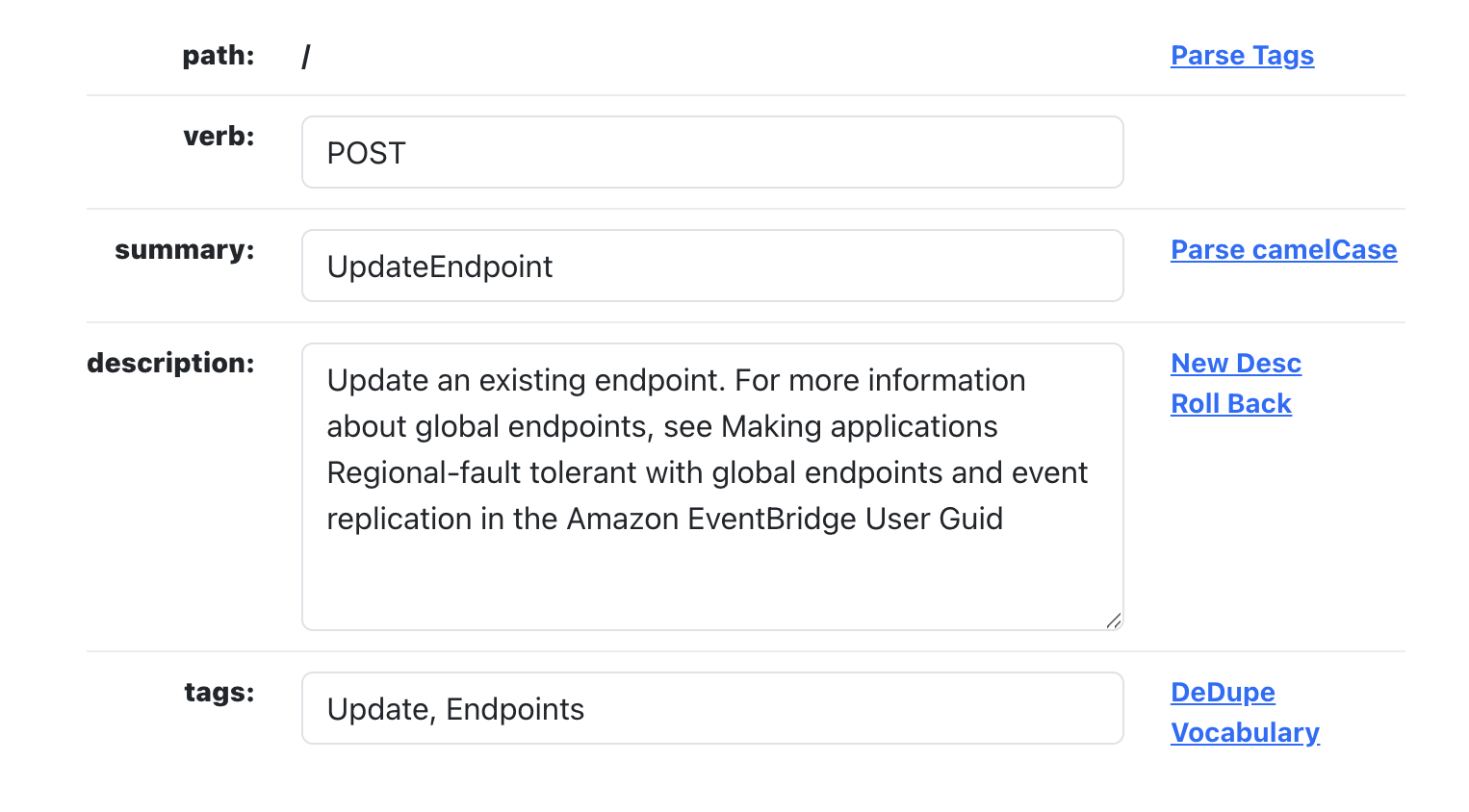
For working with OpenAPI I have another suite of functions that parse the path for tags, parses summaries that are camelCase, rewrites the description using ChatGPT, and then dedupes and runs each tag against a central vocabulary I have that deletes and translates various key words and phrases into cleaner tags.
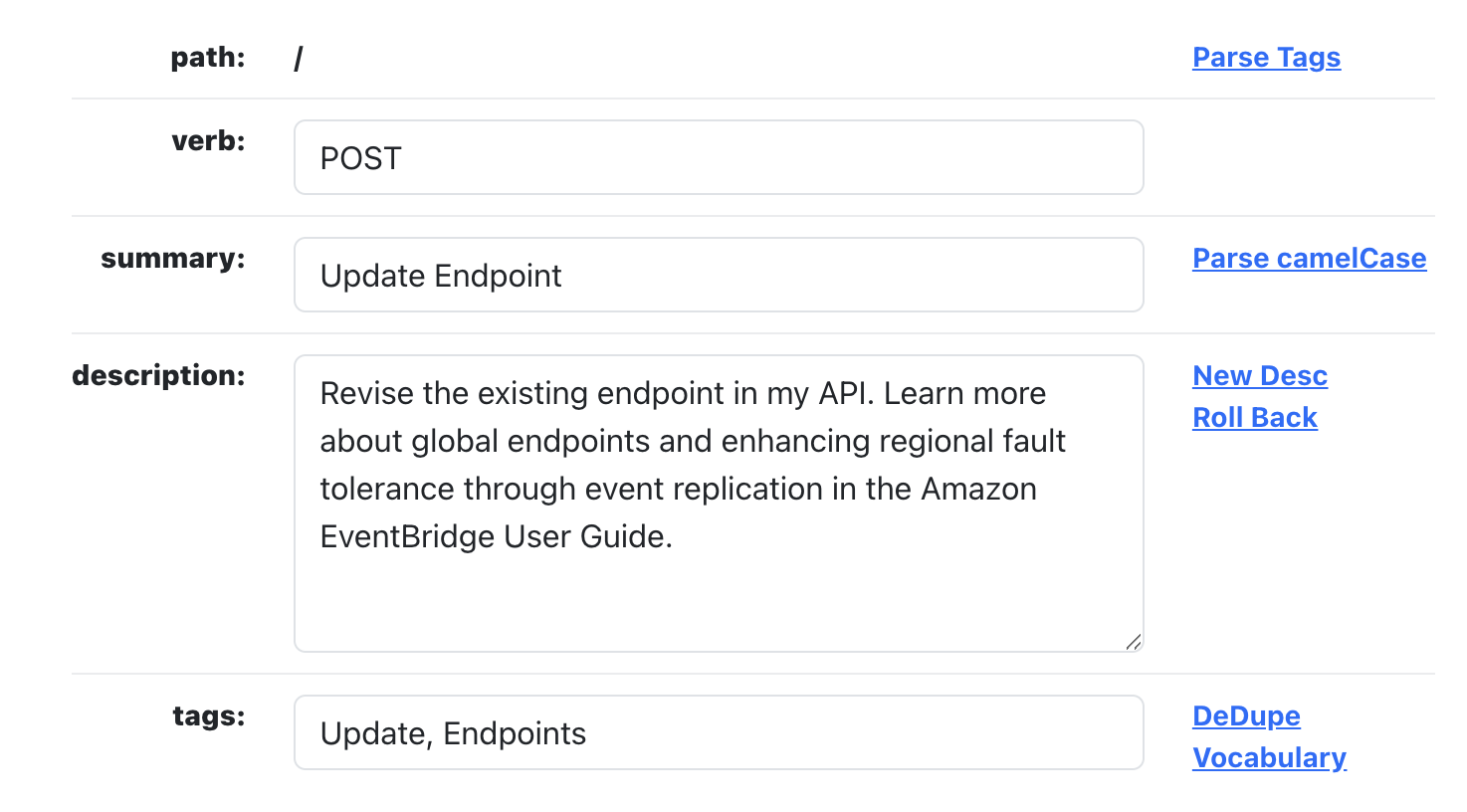
When you have hundreds of APIs and hundreds of operations this comes in pretty handy—once I stabilize I will further automate and streamline. I have functions I am working on that will not just parse URLs from API portals, but also paths, parameters, examples, and other API elements I need to further flesh out the OpenAPI.
I have this custom tool wired up to the twelve search nodes I have wired up to my v2 APIs.io search engine. Next I will continue to automate the discovery of new APIs by tag using Bing and whatever other search I wire up, perpetually crawling new potential APIs and rating the possibility it is actually an API by counting the elements found on the page.
Then I just have to strengthen how it harvests the individual API elements to assemble an OpenAPI. After that it will just be about fine tuning. Ideally API providers are doing this work and publishing an APIs.json in the root of their developer portal and maintaining all their own properties and OpenAPIs—in lieu of this, I’ll keep crawling and harvesting.
I still haven’t figured out how I will be adding new search nodes to APIs.io v2. Right now it is manual, but I can easily generate new repo and begin publishing APIs.json and OpenAPI to any search node I have. I even have my existing Artisanal wired up as my “inbox” node, the waiting room for new APIs until they have a valid OpenAPI—then I move to a search node.
Anyways, feeling pretty good about the process, and eager to keep refining how it crawls, harvests, and refines. I think there will always be a human aspect to this, but the goal is to automate away anything I can. Even using AI when it makes sense. I am confident that once I reach a certain number of Apis in the search index, other API providers will join in the fun.

