In the last six months I was fortunate enough to be able to push forward one of my side projects, with the help of a prototype grant from the Knight Foundation. The mission of the project, is to help move forward existing open federal government data projects, by adopting them, and helping clean up the data, publish simple APIs, generate more meta data, while also telling stories around the project. Something I originally called Federal Agency Dataset Adoption, but then shortened to simply Adopta.Agency.
When I was doing my final presentation in Pittsburgh last month, for the Knight Foundation, someone from the University of Miami was present, and when they got home, contacted me about helping move forward the database available at ClinicalTrials.gov. I do not know much about the data present in the collection, but immediately recognized it as a viable Adopta.Agency project.
To summarize their request, it went something like this :-)
I am working on a project that uses data from https://clinicaltrials.gov/ . Their API is crap to say the least. I was wondering if you could help me out. Is there a tool I could use to get better access to the data? If we download the entire thing is an 850MB zipped file in XML. I only need a fraction of the trials in the db. I guess I am looking for advice on how to proceed.
I get questions like this a lot, something that contributed to me pushing forward my Adopta.Agency work. The Knight Foundation prototype grant was just that, the prototype funding, something I intend to keep pushing forward, targeting new data sets, and looking for more open data activists to assist in doing the heavy lifting. The ClinicalTrials.gov database seemed like an excellent candidate because it is a high value data sets, and is something that is pretty poorly presented via the download and API (?) page available at ClinicalTrials.gov.
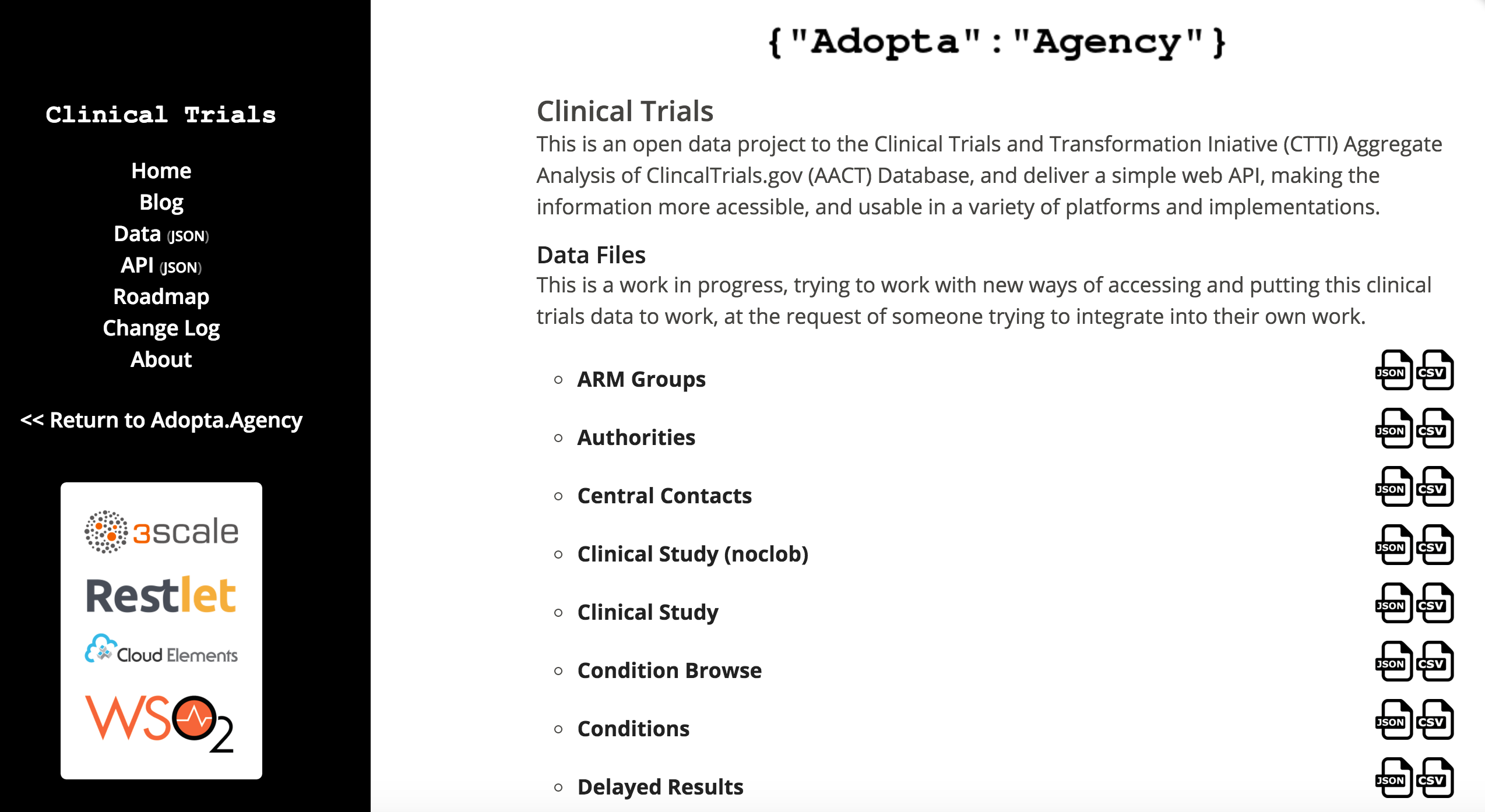
Enough talk. I got to work downloading the ClinicalTrials.gov data file, and kicking off a new Adopta.Agency project. Here is what I’ve accomplished so far:
- Import The Pipe Delimited Data Files Into MySQL
- Generate An OpenAPI Specification From The Database I Created
- Generate The PHP Slim Framework Server Code I Need From The OpenAPI Spec
- Generate CSV Files For User To Download Easily
- Generate JSON Files For User To Download Easily
- Forked The Adopta.Agency Blueprint To Manag Data And APIs
- Upload CSV and JSON Files To Amazon S3 Instead Of Github
- Use The OpenAPI Spec To Drive The API Documentation
- Managing The Support, Feedback, and Roadmap Using Github
I now have 40+ separate clinical trials data files, available as JSON or CSV, and a complete API that allows for reading and writing, plus a communication and issue management system that will help me engage with others around the project. This entire process is Github driven, with APIs.json and OpenAPI Spec as its machine readable core, which indexes everything that is going on–as it happens.
I think that the ClinicalTrials.gov project represents the Adopta.Agency mission well. There is a wealth of amazing open data sets available on the government perimeter. Much of it isn’t well defined, lacking necessary descriptions, tagging, and other meta to make it discoverable, let alone using machine readable, open data formats like APIs.json, OpenAPI Spec, and JSON Schema. I do not blame the folks in government, I understand that they are working with limited resources, and something awareness of modern open data and API approaches. This is why they need our help!
If you’d like to get involved with the clinical trials open data and API project, head over the project site, and drop me a line using the project’s Github Issue management. I am not sure what is next. I will be looking for feedback from the folks who tuned me into the data set, as well as from my own network–then I can spend some more time on the road map, and see what we can make happen.

