
I’m always looking for simpler, and cheaper ways of doing APIs that can help anyone easily manage data while making it available in both a human and machine readable way–preferably something developers and non-developers both will find useful. I’ve pushed forward my use of Github when it comes to managing simple datasets, and have a new approach I want to share, and potentially use across other projects.
You can find a working example of this in action with my OpenAPI Toolbox, where I’m looking to manage and share a listing of tooling that is built on top of the OpenAPI specification. Like the rest of my API research, I am looking manage the data in a simple and cheap way that I can offload the storage, compute, and bandwidth to other providers, preferably ones that don’t cost me a dime. While not a solution that would work in every API scenario, I am pretty happy with the formula I’ve come up with for my OpenAPI Toolbox.
Data Storage and Management In Google Sheets
The data used in the OpenAPI Toolbox comes from a public Google Sheet. I manage all the tools in the toolbox via this spreadsheet, tracking title, description, URL, image, organization, types, tags, and license using the spreadsheet. I have two separate worksheets, one of which tracks details on the organizations, and the other keeping track of each individual tool in the toolbox. This allows for the data to be managed by anyone I give access to the sheet using Google Docs, offloading storage and data management to Google. Sure, it has its limitations, but for simple datasets, it works better than a database in my opinion.
Website and Basic API Hosting Using Github
First, and foremost the data in the OpenAPI Toolbox is meant to be accessible by any human on the web. Github, using their Github Pages solution, combined with the static website tool Jekyll, provides a rich environment for managing this data-driven toolbox. Jekyll provides the ability to store YAML data in its _data folder, which I can then use across static HTML pages which display the data using Liquid syntax. This approach to managing data allows for easy publishing of static representations in HTML, JSON, and YAML, making the data easily consumable by humans and machines, in an environment that is version controlled, forkable, and free for publicly available projects.
JavaScript Spreadsheet Sync To YAML Data Store
To keep the data in the Google Spreadsheet in sync with the YAML data store in the Github hosted repository I use a simple JavaScript driven page on the website. To make it work you have to provide a valid Github OAuth token to be passed along as query string like this http://openapi.toolbox.apievangelist.com/pull-spreadsheet/?token=[github token]. The token can be acquired by doing the usual OAuth dance with Github or using the Github account of any user where you can issue personal tokens. If the user is a valid contributor on the repository, the JavaScript will pull a recent copy of the data in the Google Spreadsheet, and publish as YAML in the _data folder for the toolbox repository successfully–otherwise, it just throws an error.
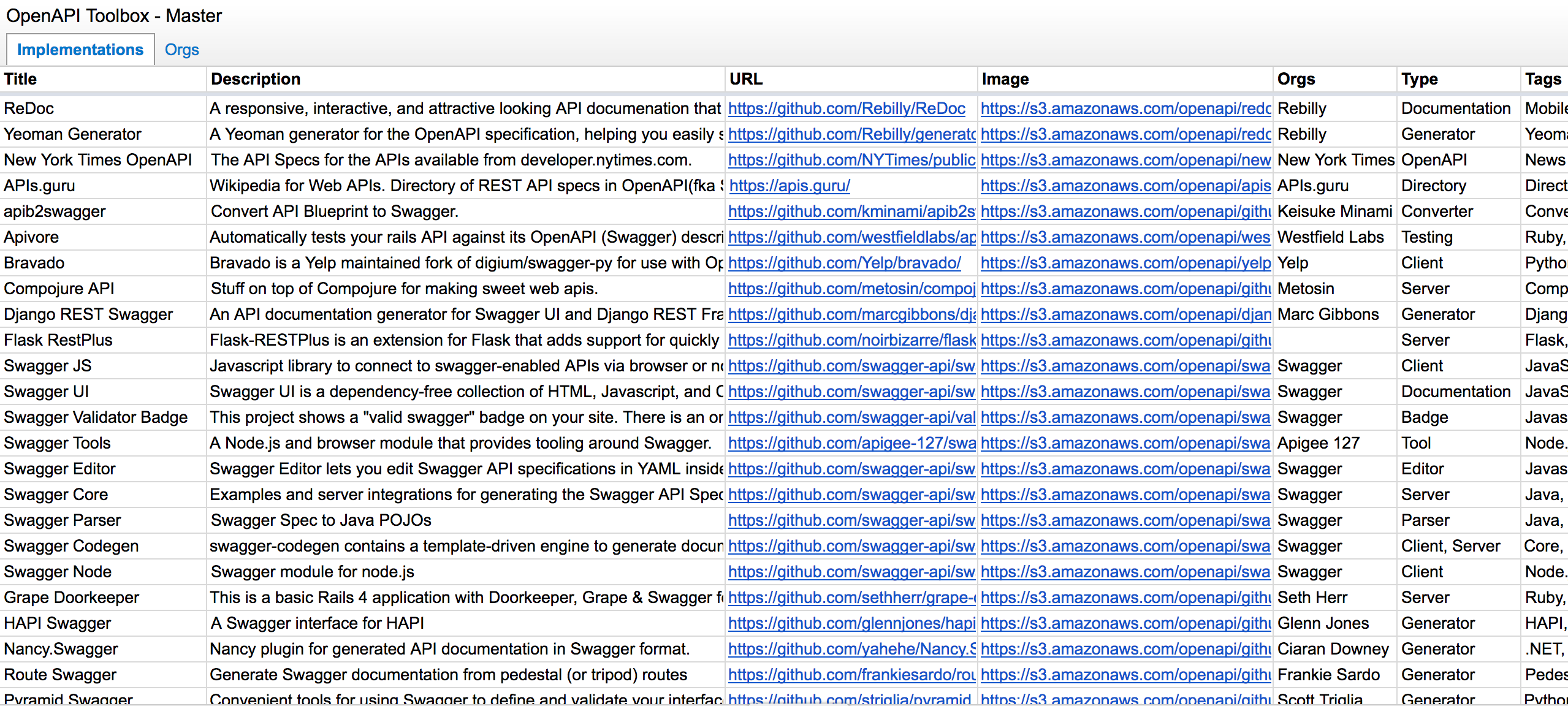
HTML Toolbox For Humans To Browse The Toolbox
Jekyll provides a static website that acts as the public face for the OpenAPI Toolbox. The home page provides icon links to each of the types of tools I have indexed, as well as to specific tags I’ve selected, such as the programming language of each tool. Each page of the website is an HTML page that uses Liquid to display data stored in the central YAML store. Liquid handles the filtering of data by type, tags, or any other criteria I choose. Soon I will be adding a search, and other ways to browse the data in the toolbox as the data store grows, and I obtain more data points to slice and dice things on.
JSON API To Put To Use Across Other Applications
To provide the API-esque functionality I also use Liquid to display data from the YAML data store, but instead of publishing as HTML, I publish as JSON, essentially providing a static API facade. The primary objective of this type of implementation is to allow for GET requests on a variety of machine-readable paths for the toolbox. I published a full JSON listing of the entire toolbox, as well as more precise paths for getting at types of tools, and specific programming language tools. Similar to the human side of the toolbox, I will be adding more paths as more data points become available in the OpenAPI toolbox data store.
Documentation Using Liquid and OpenAPI Definition
Rather than just making the data available via JSON files, I wanted to also provide simple API documentation demonstrating what was possible with the data stored in the toolbox. I crafted an OpenAPI for the OpenAPI Toolbox API, providing a machine readable definition of all the paths available. Again, using Liquid I generate simple API documentation and schema, that actually allows you to make calls against the API, using a simple interactive JavaScript interface. While the OpenAPI Toolbox is technically static, using Liquid and OpenAPI I was able to mimic much of the functionality developers are used to when it comes to API integration.
Project Support and Road Map Using Github Issues
As with all of my projects I am using the underlying issue management system to help me manage support and the roadmap for the project. Anyone can submit an issue regarding a tool they’d like to see in the toolbox, regarding API integration, or possibly new APIs they would like to see published. I can use the Github issue management to handle general support requests, and communication around the project, as well as incrementally manage the data, schema, website, and API for the toolbox.

Indexed In Machine Readable Way With APIs.json
The entire project is indexed using APIs.json, providing metadata for the project as well as other indexes for the API, support, and other aspects of operating the project. APIs.json is meant to provide a machine readable index for not just the API, which is already defined using OpenAPI, but for the rest of the project, including documentation and support, and eventually a road map, blog, and other supporting elements. Using the APIs.json index, other systems can easily discover the API, and programmatically access the data via the APIs, or even access the repository for the spreadsheet via the Github API, or the Google Sheet via its API–all the information is available in the APIs.json for use.
A Free Forkable Way To Manage Simple Data And APIs
This approach to doing APIs won’t’ be something you will want to do for every API implementation, but for simple data-driven projects like the OpenAPI Toolbox, it works great. Google Sheets and Github are both free, so I am offloading the storage, hosting, and bandwidth to another provider, while I am managing things in a way that any tech-savvy user could engage with. Anyone could manage entries in the toolbox using the Google Sheet and even engage with humans, and other applications via the published project toolbox.
I am going to continue evolving this approach to fit some of my other data-driven projects. I really like having all my projects self-contained as individual repositories, and the public side of things running using Jekyll–the entire API Evangelist network runs this way. I also like having the data managed in individual Google Sheets like this. it gives me simple data stores that I can easily manage with the help of other data stewards. Each of the resulting projects exists as a static representation of each data set–in this case an OpenAPI toolbox. I have many other toolboxes, toolkits, curriculum, and API research areas that are data driven, and will benefit from this approach.
What really makes me smile about this is that each project has an API representation of its core. Sure, I don’t have POST, PUT, and DELETE capabilities for these APIs, or even advanced search capabilities, but for projects that are heavily read only–this works just fine. If you think about it though, I can easily access the data for reading and writing using the Google Sheets or Github APIs, depending on which layer I want to get access at. Really I am just looking to allow for easy management of data using Google Sheets, and simple publishing as YAML, JSON, and HTML, so that humans can browse, as well as put to use in other applications.

