My friend David Kernohan (@dkernohan) emailed me the other day asking me for some advice on where to get started working with some data APIs he had been introduced to. This is such a common question for me, and surprisingly seven years into API Evangelist they are questions I still do not have easy answers for. Partly because I spend the majority of my time writing about providing APIs, but also because API consumption is often times inconsistent, and just hard.
David provided me with two sources of data he wanted to work, which I think help articulate the differences between APIs, that can make things hard to work with when you are just getting started with any API. Let’s break down the two APIs he wants to work with:
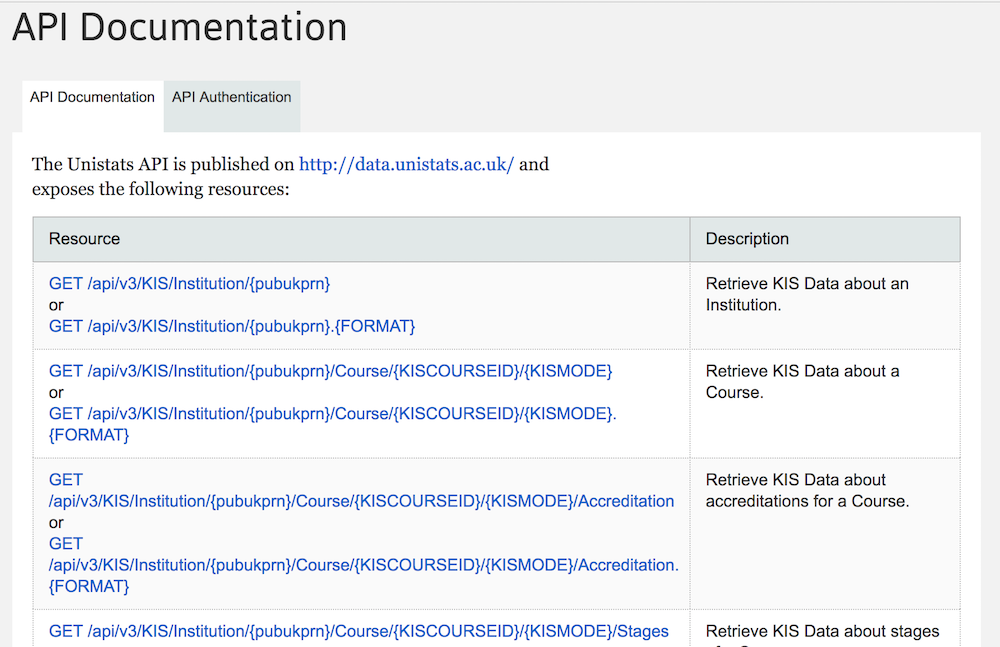
- UNISTATS
- Description: Compare official course data from universities and colleges.
- URL: http://dataportal.unistats.ac.uk/Pages/ApiDocumentation
- Details: It is an API with 8 separate paths to get what you need.
- Resources: Institution, Course, Stages, Accreditations, Locations, Statistics
- Data Type: XML & JSON
- Authentication: Basic Auth
- Higher Education Funding Council for England (HEFCE) Register of Higher Education Providers
- Description: The HEFCE Register is a searchable tool that shows how the Government regulates higher education providers in England.
- URL: http://www.hefce.ac.uk/reg/register/data/
- Details: Downloadable files with 6 urls available.
- Resources: Providers, Courses
- Data Type: XML, CSV
- Authentication: Auth: NONE
Here you have two sources of data that overlap. One is actually an API, which you can change paths, parameters, and get different JSON or XML results. The other is just a download of an XML or CSV file. One has authentication using BasicAuth, which is a standard way of logging into websites, which often is reappropriated for accessing web APIs. You can start to see why API consumption can become pretty overwhelming, pretty quickly.
CSV Is Easier So where do we start? Well with the HEFCE downloads you get the results in CSV, something you can quickly upload into a spreadsheet and get to work. This is pretty straightforward data 101 stuff, making CSV and the spreadsheet still number one when it comes to working with data–a wide audience. However, the core dataset David wanted to work with from UNISTATS is an API, with JSON and XML returned. I know us API folk like to think of APIs as opening up access to data, but this chasm is one that many folks aren’t going to be able to step over.
XML is Harder Let’s begin with the pulling a list of institutions in XML. Before I can get at the data I need to sign up for an account. After signing up I am given a key which I can use to authenticate the first time I try to load the URL http://data.unistats.ac.uk/api/v3/KIS/Institutions.xml–there are more details about authentication as part of their documentation. As soon as I download this file, I double click on it to see which application will try to load it–Microsoft Word happily steps forward to assume the responsibility. However, it does me little good, and just loads a big XML blog in a documentation–what do I do with that? Next, I try with Microsoft Excel with the same results. Google Drive gives me the same response, uploads as XML, and loads as a blog with no recognition by Google Docs or Spreadsheet. So what now?
We have a set of CSV files, and potentially a set of XML files, after making our way through each available path of the UNISTATS API. We need to get the XML into Google Sheets, or Microsoft Excel. The CSV is easy, the XML is hard–we will need to convert from XML to CSV. We could accomplish this with the Google Sheets importXML function, but because the API requires authentication it would need some programming–I wanted to keep this code free if possible for now. We are able to authentication with the UNISTATS API via our browser and download the XML with this API, so writing code, even a Google Script seems over the top.
XML To CSV Conversion I recommend using a simple tool like XML To CSV Converter, and not overengineering this time. You can just download the XML returned from the UNISTATS API, save to desktop and upload to the XML to CSV Converter to get the CSV edition. Then the data from the UNISTATS API and the HEFCE downloads, all CSV format now can be uploaded to Google Sheets, or imported into Microsoft Excel for working with. This process can be repeated as necessary, whenever the data is updated on each of the sites–no coding necessary.
Reusing This Process For Future APIs This process worked with these two APIs. Next time you are working on a project the APIs could have different types of paths available, returning XML, JSON, CSV, or other configuration. They might have different types of authentication requiring API keys as a parameter, or maybe even OAuth–raising the bar even higher when it comes to connecting. Most importantly, sometimes the data returned might not be neat columns and rows, and not be compatible with working within a spreadsheet. Many APIs return “flat” data like we encountered this round, but an increasing number of APIs are returning much more structured forms of data that won’t simply import into a spreadsheet.
For this API exercise, we were able to take care of business using the browser. We were able to download the CSV, and the XML from the API using the browser as a client–no coding necessary. This is a really important element of understanding APIs. Websites return HTML for browsers to show to humans, and web APIs return XML, JSON, CSV, or another machine readable format for use in ANY application–in this case, it was a spreadsheet that will help us take things to the next level and figuring out what we want to do next with this data, to make sense of things.
Look At Leading API Clients – No Code Necessary For future API projects, I recommend taking a look at the Postman, or Restlet API client. Which will help act as a client for working with simple, and more complex APIs–helping you with authentication, headers, and other aspects of consuming a diverse range of APIs. These clients allow you to connect to APIs, and work with the XML, JSON, CSV, and other responses you will receive. Of course you will still have to download, convert, and upload resulting data into whatever application you intend to work with data within. These are simply clients, not applications that will help you transform, analyze, visualize, and make sense your data–it is up to you to do this.
Some Final Thoughts On API Consumption Despite almost 17 years of evolution web API consumption is still hard, and in the realm of programmers. Google Sheets and Microsoft Excel have tools to help you pull in data from APIs, but authentication and complex data structures will always be an obstacle in this environment. For more complex API integrations I recommend adopting an API client like Postman or Restlet, which will augment Google and Excel spreadsheets in your toolbox. Beyond that, I encourage using Github for publishing CSV, JSON, or YAML that is returned from APIs, and telling stories around the data using Github Pages. Github has been working hard to build in features for working with CSV, JSON, and YAML data, again making it possible to work with data returned form APIs with no, or minimal coding–Github employs Jekyll, which in turn uses Liquid + HTML, but is something totally still within the realm of non-programmers.
Learning how to consume APIs is a journey, not a destination. APIs come in many shapes and sizes, but if you grasp the basic of the web, and have some of the right tools in your toolbox, you can navigate them and put them to work. I’m going to work on some more Google Spreadsheet examples, as well as some Postman and Restlet examples, using some of the most common APIs out there like Twitter, Flickr, and others. I’ll check back with David in a couple weeks to see how he is doing when it comes to onboarding with the APIs he has targeted for this project, and see where I can help him in his journey.

